A Closer Look at Run Estimation
“Would a system that placed nickels, dimes, quarters, 50-cent pieces on the same basis be much of a system whereby to compute a man’s financial resources? And yet it is precisely such a loose, inaccurate system which obtains in baseball…”
– F.C. Lane, the editor of the Baseball Magazine from 1912-1937, and statistical pioneer
Several weeks ago I wrote an article titled “Run Estimation for the Masses” which took a closer look at the increasingly fashionable On-Base Plus Slugging (OPS) statistic in order to see how it compared as a proxy for offensive production to run estimators and other measures and just why it stacked up so well against them.
I’ll save you the trouble of going back through the article and summarize the results. Using correlation coefficients, I showed that OPS tracks extremely well with actual runs scored at the team level, and that as a result it actually belongs in the same group as the more complex run estimators, such as Bill James’ Runs Created, Pete Palmer’s Batting Runs, David Smyth’s BaseRuns, and Jim Furtado’s Extrapolated Runs. The simpler statistics such as home runs, walks, slugging percentage, on-base percentage, and batting average aren’t in the same class as these others when it comes to correlating with runs scored.
This close correlation is therefore what justifies its use as a shorthand way of characterizing a player’s offensive contribution. In short, it has the right mix of simplicity and accuracy to be a useful approximation for “back of the envelope” calculations of player value. I concluded by using a little algebra to show that when broken down into its constituent parts, OPS is fundamentally a kind of linear approximation of these more complex formulas.
While using correlation coefficients is an acceptable way of comparing runs estimators with other measures like OPS, this week in response to some inquiries by readers, I want to complete that discussion by illustrating the different ways of comparing the pure run estimation formulas, and then tackle the questions that inevitably bubble to the surface when this topic is discussed.
Run Estimators 101
Before looking at other ways we can compare run estimators, we should first be clear on what we mean by a run estimator, and take a look at how they are constructed. In the literal sense, a run estimator is a formula that attempts to calculate the number of runs that “should” be scored, given some set of offensive elements. In other words, a run estimator is simply a formula that models run scoring when applied to a set of counting statistics, such as at bats, hits, home runs, etc.
By definition, then, statistics like batting average, slugging percentage, and OPS are not run estimators, while Runs Created, Batting Runs, and BaseRuns are. The key strength of run estimators is that they take into account the offensive context—outs and opportunities in the form of plate appearances—to return the number of runs. Even though OPS correlates well with run production, it lacks this crucial element, and so if you compare team A with an OPS of .750 to team B with an OPS of .760, that doesn’t give you a sense for how many runs the team should have scored and the difference between the two teams.
For this article, then, we’ll look solely at the run estimators listed below. Since run estimators are sometimes a bit of a religious issue among the initiated, let me first provide a few caveats.
First, it should be noted that these formulas were developed against the backdrop of specific data sets. For example, the versions of Extrapolated Runs used here were created to best fit the period from 1955-1997, Batting Runs was originally developed using data from 1901-1977, and Runs Created has been more recently tweaked. All of them could (and I would argue in a perfect world should) be tailored to better fit a particular set of teams, for example a specific league and year, or the 2000-2005 data set I was working with.
The reason these formulas could be modified when working with different data sets is because the offensive context changes from season to season and between leagues. For example, it is common sense that a triple is worth more in a low run scoring environment like 1968 (the “year of the pitcher”,) when Bob Gibson recorded his 1.12 ERA and Carl Yastrzemski won the batting title with his .301 average, than it is in the higher run scoring world of 2001 when both Barry Bonds and Sammy Sosa hit more home runs than Roger Maris in 1961. Conversely, the cost of an out is smaller when runs are scarcer than it is when runs are plentiful (since in the latter case each out represents a greater opportunity lost). You’ll notice that all of the formulas below apply various weights to offensive elements either in terms of runs or base runner advancement. As a result, those weights given to triples, outs, and the other elements should rightfully vary in accordance with the context. The fact that analysts don’t typically take the time to adjust for variations in context is a simplification used for convenience (who wants to manage all of those formulas anyway?).
That said, the creators of both Batting Runs and BaseRuns include explicit ways to customize the formulas for team and league context. I used the adjustment for BaseRuns in my article “Are You Feeling Lucky?” published in The Hardball Times Baseball Annual 2006 by fine-tuning what’s known as the “score rate” for 2005. In the case of Batting Runs the formula can be tweaked by changing the negative run value of an out, as I’ll describe below. This adjustment, termed the “league batting factor” or ABF is used to ensure that the total Batting Runs equal zero for the given league and year. Along these lines, adjustments could be made to the out value for both Extrapolated Runs formulas shown below as well. Incidentally, in order to be able to compare Batting Runs with the other estimators we can also adjust the value of an out to transform the formula from one that returns runs above average into one that returns total runs.
Secondly, there are multiple versions of each of these formulas in the public domain and I chose only one of each variety for this analysis. You’ll notice that they don’t all include the same offensive elements, and so the results shouldn’t be taken as proof that a particular construction is necessarily superior to another. Your results may vary if you use more complex variants or if you use a different data set. My aim here is simply to show how the formulas can be compared.
Third, it should also be noted that I did not include Clay Davenport’s Equivalent Average (EqA), which is used by Baseball Prospectus, not because I don’t appreciate it, but because technically it is not a run estimator, since it requires a separate formula to transform EqA to produce Equivalent Runs (EqR). I also did not include Paul Johnson’s Estimated Runs Produced (ERP), since it is essentially a derivative of the Batting Runs and Extrapolated Runs formulas.
And finally, this kind of analysis has been done by others including Furtado and John Jarvis, using similar measures, so don’t think I’m being all that original here.
The Formulas
The following are the formulas I’ll use in this article.
Runs Created (RC)
This is the more complex version of the formula introduced in The Bill James Handbook 2005, that includes stolen bases and minor categories such as grounded into double play, intentional walks, sacrifice hits, and sacrifice flies. The formula contains A, B, and C components representing base runners, advancement, and opportunities, respectively, that are calculated as follows.


And then these components are combined in the formula …
Runs Created Basic (RC-Basic)
This is one of the most basic versions of the formula created by Bill James in the 1970s. This is essentially equivalent to on-base percentage multiplied by slugging percentage, and, as you can see, it uses the same basic A, B, and C components.
Batting Runs (BR)
This is the offensive component of Pete Palmer’s Linear Weights system, as discussed in The Hidden Game of Baseball, which he originally derived using computer simulation. The formula I’m using is based on the version from the 2004 edition of The Baseball Encyclopedia, where the value of an out is set to -.10 rather than adjusted for the league as noted above, where the typical ABF values for particular leagues and years range from -.23 to -.28.
The reason the value I’m using here is lower is because ABF is calculated so that BR returns runs above average. In order to compare this formula to the others it is therefore necessary to split the ABF, that is the value of an out, into two parts: the inning-ending value and the advancement value. The basis for this is straightforward as has been written about by Tangotiger. The value of an out (or any offensive event for that matter) can be thought of as the sum of the value of reaching base, the value the event has in moving runners over, and the value it has related to ending the inning. Using the run environment of 4.3 runs per game (the average runs per game from 1901-1977), each out is “worth” -.16 runs in terms of its inning-ending value (4.3/27). Subtracting -.16 from -.26 yields an advancement value of -.10, which we’ll use in the formula.
You’ll notice the formula also includes stolen bases and caught stealing.
Extrapolated Runs (XR)
This is full version of the formula published by Jim Furtado in the 1999 Big Bad Baseball Annual, which includes intentional walks, sacrifice hits, and sacrifice flies as well as grounded into double play. Furtado created his formulas by using linear regression.
![]()
![]()
And then XR is calculated as:
Extrapolated Runs Reduced (XRR)
This is Furtado’s simpler formula and also includes stolen bases.
BaseRuns (BsR)
This is the formula David Smyth developed in the early 1990s, for which you can find many variations. The variation I’m using was published on Tangotiger’s site several years ago, and is fairly basic, since it does not contain the minor elements other than hit by pitch. Since that time, Smyth has published an updated version in June of 2005 on the Strategy and Sabermetrics forum, although I found this one more accurate for the data set I was working with.
This formula contains A, B, C and D components representing base runners, the advancement of those runners, the number of outs, and of course home runs, and is calculated as follows:
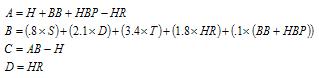
The interesting aspect of BaseRuns is that the B and C components are combined to calculate a “score rate” that attempts to estimate how often base runners score. When this ratio is multiplied by the number of base runners (A) and added to the number of home runs you get an estimate of the runs that would be scored as shown below.
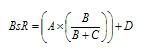
Proponents of BaseRuns argue that this model is the only one that truly models how runs are scored, and some simple calculations using extreme run environments (think your average beer league softball game) prove that out. Of course major league baseball is not played in these extreme environments, and so all of the formulas tend to give similar results when OBP ranges from .300 to .400 and slugging percentage from .300 to .500.
The Results
In my previous article I used correlation coefficients (referred to simply as r) as a measure for how well a statistic like OPS or Runs Created stands in for offensive performance. While r is a good start, it only measures the strength of the linear relationship between two sets of values, with -1 being a perfectly negative or inverse relationship and 1 a perfect positive correlation. In other words, a high r value for OPS like .948 indicates that the general ordering of both runs scored and OPS is very close.
But that’s not the end of the story. Although a run estimator may have an r value very close to 1, that doesn’t necessarily mean it does a great job of predicting the actual number of runs a team scores. For example, I could create a statistic based on OPS, such as OPS+63, that has a high r value by virtue of its’ incorporating OPS, but doesn’t come close to returning the number of runs. As a result, one should also consider measures like the average error per team, and the spread of those errors across all teams.
The following table includes those measures applied to the 180 teams from 2000-2005. The columns include the r value, the mean error (ME, calculated as the average of the sum of the estimate minus the number of runs the team scored), the mean absolute error (MAE, calculated as the average of the sum of the absolute values of the estimate minus the number of runs the team scored), the standard deviation (SD, which measures the spread of the differences between the number of runs the team scored and the estimate) and the root mean square (RMS). RMS is what is known in statistics as a power mean, and is a combination of the MAE and SD and is calculated as:
RMS represents the magnitude of the varying quantity. In other words, it’s a handy way to take into consideration both the average error and the distribution of those errors and distill them in a single number for comparison.
Estimator r ME MAE SD RMS RC 0.9604 6.52 19.2 14.68 24.14 BaseRuns 0.9549 1.78 18.8 16.76 25.22 XR 0.9595 10.90 20.6 15.94 26.05 RC-Basic 0.9526 6.72 20.3 16.62 26.26 Batting Runs 0.9539 6.96 20.1 16.71 26.15 XRR 0.9562 12.39 21.9 16.85 27.61
As you can see BsR has the lowest MAE, while RC has the lowest SD. Taking both into consideration, RC outperforms BsR by a fraction when compared using RMS. Another way to think about this is that while BsR on average comes closer than RC, the distribution of its errors is larger (for the variant I used anyway) than any of the other estimators except XRR. It is therefore more likely that a specific BsR value is either closer or wider of the mark. For example, using BsR, 71 of the 180 teams had estimates that were within 10 runs, while the next highest was 61 for Batting Runs. At the same time, however, BsR had estimates for 7 teams that were off 60 runs or more, while all the other formulas except XRR had fewer than that.
You can also see from this that although XRR has a higher correlation coefficient than BsR, and yet it also had both the highest MAE and SD, and was therefore ranked last in RMS. This drives the point home that correlation coefficient isn’t necessarily the best way to compare run estimators.
We can view the distribution of the errors graphically by looking at the number of teams that fall within certain error ranges. Below you can see Runs Created plotted against BaseRuns.
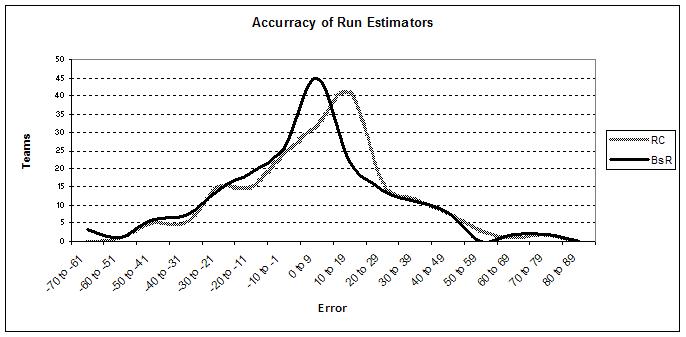
As you can see the apex of the curve for BsR is higher and centered around the 0 to 9 grouping, indicating that it more often gets closer to the mark, hence its lower MAE. However, the left-hand tail of RC remains under that of BsR, indicating that when it underestimates the actual runs scored, it does so with a smaller error. RC also sneaks under BsR on the far right-hand side as well.
The shifted nature of the graphs also illustrates that Runs Created tends to overestimate actual runs more so than does BsR, as evidenced by its ME of 6.52, as compared to 1.78 for BsR.
Here’s a second graph showing XR along with its cousin BR.

Here, it’s obvious that XR tends to have a more compact distribution, although BR is more centered in the -10 to 10 run error range. It’s also clear that XR is less prone to underestimate the number of runs scored and more prone to overestimate it, as is evidenced by the higher ME of 10.90 for XR versus 6.96 for BR.
And for completeness here are RC-Basic and XRR.
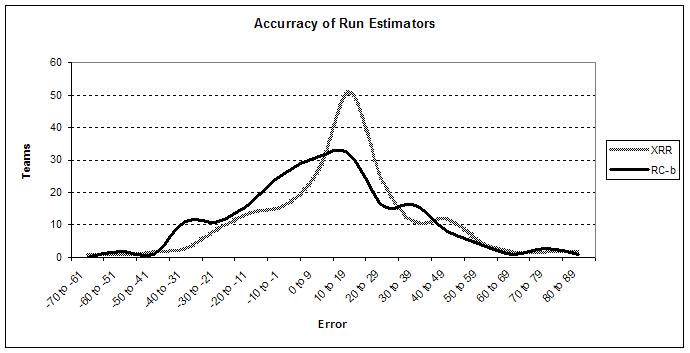
Interestingly, although XRR has the highest MAE at 21.9 and SD at 16.85, its distribution appears more compressed than that of RC-Basic. The reason is that extreme values carry greater weight in the calculations and XRR was off by 40 or more runs on 27 of the teams, while RC-Basic did so just 22 times. In addition, the curve for XRR is clearly shifted to the right as evidenced by its ME of 12.39 so that it has by far the fewest number of teams in the -10 to 10 range.
Although the different run estimators have different distributions and tend to make the same kinds of errors overall, it should be noted that they also make errors on the same teams. For example, all of the estimators agree that the 2002 Phillies “should” have scored more than their 710 runs by a wide margin.
RC 782 BR 796 BsR 786 XRR 795 XR 789 RC-Basic 778
As a result, the differences in estimations for any one team is fairly small, as in this case here where it varies by 18 runs. Variables that tend to throw these estimates off include especially good or especially poor hitting with runners on base (the 2002 Phils hit .250/.338/.398 with runners on and .266/.340/.441 with the bases empty), or offenses where one or two individuals carry the lion’s share of the load.
But that brings us to the larger question regarding these run estimators.
But What About the Players?
Keep in mind that each of these formulas is a run estimator , and as you can see they all do a pretty good job of estimating runs at the team level. From the best to the worst they vary by just 2.1 runs per team in the mean error, or just over a tenth of a run per game. All told, the mean absolute error ranges from 2.4% to 2.8% per team. As a result, any of these formulas can reasonably be used to estimate how many runs a team should have scored given a set of events. And as mentioned previously several can be made more accurate by adjusting for the league context.
Where most of the value of these formulas lie, however, is in applying them to individual players and from there calculating more advanced measures like Batting Runs Above Replacement (BRAR), as they do at Baseball Prospectus, or Win Shares, as we do on our site, in order to pin a value on a player’s contribution.
It should be noted that this idea is nothing new. A frustrated F. C. Lane (as you can tell from the quote that begins this article), as early as 1916, took it upon himself to record 1,000 hits and their results in order to assign them coefficients to use in an equation he developed. Using that data he derived weights for singles, doubles, triples and home runs of .30, .60, .90, and 1.15. The core of Lane’s observations of the 1,000 hits was that hits were not only valuable for the obviously different number of bases gained by each, but there was also a component of advancement value that contributed to run creation. Later Lane also assigned a value of .164 to walks, a value now recognized as too low by half but revolutionary for its time by crediting a walk on the batter’s part as valuable at all.
It should also be remembered that Lane’s innovation came in a time when batting average, made official way back in 1876, was the only way most people had ever evaluated offensive players. It is true that Henry Chadwick developed a stat in the 1860s he called “Total Bases Per Game”, which was slugging perentage with a different denominator, but it didn’t really catch on, and slugging percentage was not made official in the National League until 1923 and the American League until 1946.
Lane used his run estimation formula to compare Brooklyn first baseman and former batting champion Jake Daubert to Phillies slugger Gavvy Cravath, who had hit 24 home runs in 1915. Not surprisingly, Lane’s analysis showed that Cravath was the more valuable player, with a Total Run Value of 79, versus 62 for Daubert. Unfortunately, Lane’s pioneering work was all but forgotten soon after.
But be that as it may, today when run estimators are applied to individuals, there are two approaches that analysts use depending on what they’re trying to measure. For some, run estimation for individuals is an exercise in trying to determine how many of the runs a team actually scored should be credited to an individual player; in other words, their aim is to put the player in his team context. This is the approach taken by James in his annual Bill James Handbook and in assigning the responsibility for actual runs scored in his allocation of offensive Win Shares. For others, exactly the opposite is the goal as they attempt to take a player out of his team context in order to assign a value to a player’s offensive contribution and compare him to players on other teams and eras.
In both cases, however, we first have to answer the question of whether run estimation formulas that are designed and validated at the team level can actually be applied to individuals.
At first glance the answer should obviously be yes. After all, if a team can be projected to score X number of runs given a specific number of at bats, hits, doubles, and so on, then a player can be said to have “created” (contributed, produced, etc.) Y number of runs given his at bats, hit, doubles etc. However, statisticians are quick to point out that inferences about individuals based on aggregate data don’t always hold. This is the core of the so-called “ecological fallacy”.
As an example of the ecological fallacy, consider the case of the 2000 presidential election, where a study reveals that there is a strong correlation between states with higher percentages of African American voters and states voting predominately for George W. Bush. The problem of course is that from that aggregate data you can’t then infer that African American voters are more likely to vote Republican. In fact, 90% of African Americans voted for Al Gore. The fact that African American voters made up a smaller percentage of the total number of voters, and that southern states contain a much greater percentage of white voters who voted for Bush, conspire to bring about this result.
While I certainly empathize with the concern, I and other analysts don’t agree that run estimators suffer from this problem. The key difference between examples that illustrate the ecological fallacy and run scoring in baseball is that in those examples there is an interaction of multiple groups with different attributes that act independently, as in the case where black and white voters with different voting patterns and population sizes. In baseball, it is the individual players that create runs for the team, working in concert towards the same goal that is achieved in the same way, and so logically the coefficients derived for run creation at the team level must apply to the individual.
So assuming the formulas can be applied to individuals, there is a second issue that often comes up in these discussions. In looking at the formulas above you’ll notice that there is a fundamental difference in their construction that allows us to place each into one of two camps.
Runs Created and BaseRuns are multiplicative formulas, while Batting Runs and Extrapolated Runs are linear formulas. In other words Runs Created and BaseRuns both model run scoring in a non-linear and interdependent fashion with respect to offensive events, while linear estimators like Batting Runs apply run weights to offensive events and sum the totals. What this means is that in multiplicative formulas the offensive elements interact with each other to produce run estimates. The weights used in multiplicative formulas should therefore be thought of as applying advancement values to offensive elements. As a result multiplicative formulas, give higher estimates for the number of runs as the frequency of offensive events increase, while linear estimators, as the name implies, increase in a straight line. This difference is illustrated graphically below, where as the OPS increases (in the context of 650 plate appearances) the multiplicative estimator increases faster than the linear estimator.

As you can probably guess from this graph, however, in practice this difference has little effect when the formulas are applied to team statistics, since baseball is not played anywhere near the extreme ends of this graph (team OPS values typically hover in the .730-.780 range). However, when applied to individuals, these differences are immediately noticeable as players like Albert Pujols and Bonds benefit from their own offensive elements interacting with each other.
Of course, a player does not interact with his own statistics to create runs, but rather with his teammates; this led James in 2002 to modify his formula for individuals and place the player in the context of eight other players with a .300 OBP and .400 SLG, by changing how the A, B, and C components are combined.
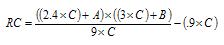
You can see that the A factor of the equation has been modified to include 8 other players with a .300 on base (8 x .300 = 2.4). The B factor has been augmented with 8 players with a .400 slugging percentage (8 x .400 = 3). The C factor then includes the plate appearances for all 9 players. After performing the (AxB)/C, the runs created by the other 8 players are removed by multiplying the plate appearances for one player by .9. This works since the runs created by 8 of the typical players are equal to 10% of the plate appearances – a quirk of using the .300 OBP and .400 SLUG.
It should be noted that he also modified the formula to adjust for the player’s performance with runners in scoring position – something I haven’t done here.
The following graph shows the adjusted version along with BsR.
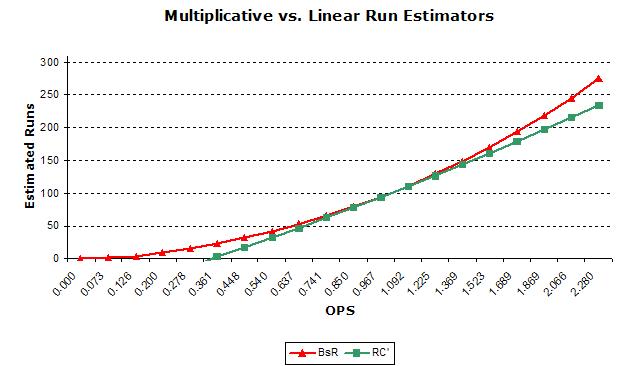
From this you can also see that BsR doesn’t have the problem to the same degree, since home runs are largely separated and so don’t interact as heavily with the other elements. You’ll also notice that it rather nicely intersects at 0, while the adjustments to RC serve to make the formula essentially linear and force it to intersect the X-axis at an OPS of around .350. This illustrates why proponents of BsR find the formula so elegant and claim that it is the only formula that accurately models run scoring.
And finally, when applying these formulas to individuals, you have the same issue as when applying them to teams, and that is the context. In actuality the offensive context changes not only with leagues and seasons but also with teams, batting order, parks, and so on. Although the various coefficients applied to the offensive elements won’t change that much for a particular lineup position on a particular team, there is a subtle difference between them. Therefore an analyst attempting to allocate a team’s runs scored to individual players should technically adjust the formula for as many of these context issues as possible.
The Score
So where does that leave us?
As mentioned previously, there are few topics which divide the performance analysis community more than run estimation. However, when you boil it down I think there are two important points for the thinking fan. The first is that the number of runs that are scored can be predicted from the combination of offensive elements quite closely using any of the popular formulas, with the caveat that the performance falls within reasonable ranges. And secondly, the formulas can indeed be applied to individuals. Together that means that thinking fans can and should embrace these tools and thank their creators Lane, Palmer, James, Furtado, and Smyth, which help all of us understand a little better, and hopefully appreciate the game a little more.