An argument for FanGraphs’ pitching WAR
A couple of weeks ago, I wrote about the correlation between team wins and a team’s cumulative Wins Above Replacement (WAR). There was a very high correlation between the two, but as Tom Tango noted on the Book Blog, this correlation was due to the fact that Baseball-Reference’s WAR is perfectly correlated (r = 1) with total runs. Runs are highly correlated with wins; thus, Baseball-Reference’s WAR should be highly correlated with team wins.
But Tango did make an interesting distinction about the correlation (r) when using FanGraphs WAR:
In fWAR, you’ll get a lower r, and that’s because of the BABIP/FIP issue, which is a design/bug, as the reader sees fit.
The correlation between rWAR (Baseball-Reference) and wins is higher than fWAR’s (FanGraphs), because rWAR uses runs allowed as its starting point for pitchers, while fWAR uses fielding independent pitching. For a full explanation of the differences between the two calculations of pitching WAR, you can follow this link.
There is a question right now in the sabermetric community about whether or not pitching WAR should be based on the runs a pitcher gives up (RA9 or runs allowed), or his three true outcome performance (walks, strikeouts and home runs; the components of FIP). Both RA9 and FIP are metrics with components that are outside a pitcher’s control.
Team defense, park factors, variation of balls in play (BABIP), umpiring (balls and strikes) and quality of league (opponents) are all factors outside a pitcher’s control that affect the number of runs he allows. Park factors, umpiring and quality of league are factors outside a pitcher’s control that affect his FIP.
Pitching WAR attempts to adjust for these factors (except for umpiring, of course) to get a true reflection of a pitcher’s value over the course of a given season.
What makes the difference so intriguing is that we really don’t know which one, rWAR or fWAR, does a better job of reflecting a pitcher’s true performance. Here are a few questions that come to mind that reflect why it’s so hard for us to know which metric is better:
{exp:list_maker}How do we know that rWAR takes out a defense’s full effect and leave us solely with the pitcher’s performance?
Is the fact that fWAR leaves out runs, and has a lower correlation with team wins, a problem?
Is FIP a reflection of past performance, an ERA predictor, or both?
Is what has happened ever as important as what will happen? {/exp:list_maker}The first question is nearly impossible to answer, because measures of defensive performance aren’t perfect, and it’s almost impossible to test whether a team’s defense plays better or worse behind certain pitchers.
The answer to the second question depends on what WAR is supposed to do as a metric. If WAR is supposed to be a reflection of true talent or real performance, then it doesn’t matter. But if WAR is supposed to tell us where wins came from on the field, then it probably is a problem.
As for the third question, I’ll let FanGraphs’ Sabermetric Library speak:
FIP does a better job of predicting the future than measuring the present, as there can be a lot of fluctuation in small samples.
I have heard the argument that FIP is better at measuring present performance than RA9, though. Our own statistics glossary here at THT states that:
FIP helps you understand how well a pitcher pitched, regardless of how well his fielders fielded.
That statement is quite obviously in the past tense, thus making the claim that FIP tells us about a pitcher’s present or past performance.
The fourth and final question is what really matters. In the piece I referred to from the outset, in which I ran the correlation between WAR and team wins, I made this statement:
WAR does a very good job of describing what has happened in a given season; however, that isn’t always very useful. Predicting outcomes in future seasons is almost always more important (valuable) than describing what has happened before
Tango seemed to agree with this statement in his response to that piece, as he stated multiple times that the fit or correlation between WAR and next-season wins is “important.” For example, telling us what happened in 2012 matters a great deal less than predicting what will happen in 2013, because we already know what happened in 2012.
This point brings about the idea that maybe fWAR is more worthwhile because of its predictive components like FIP.
Which brings me to the main hypothesis behind this post, which I’ve seen float around various discussion boards and comment sections on sabermetric sites; rWAR is better at telling us what happened, while fWAR is better at telling us what will happen.
The first part of that hypothesis is nearly impossible to test, but the second (predictive, and possibly more important) part is perfectly testable. But I wondered, how exactly should I got about testing it?
Method
I’ve found this to be the best advice: Whenever you think you have an insightful sabermetric theory or hypothesis that you want to test, but you’re not certain the best way to do it, simply ask the “master.” The master that I’m referring to is of course, Tom Tango, whose name has popped up all over this article already. Mr. Tango was kind enough to suggest a test for this idea; here are some brief snippets of how Tango thought I should go about this test:
WAR = (rate minus baseline) x playing time
So, if you are going to use WAR, either as the independent value (x) and/or the dependent value (y), you are going to include playing time. Is this really what you want?
Let’s say it is NOT WAR that you want. In that case, you’ll make life easier. You convert fWAR and rWAR into a rate stat. Which is easy enough, since we’ll convert it into a per-PA stat.
You will have some problems, because of pitchers who pitch in front of the same fielders and the same park.
So, really, what you want to do to test is to only look at pitchers who change teams. Then you will get a fair test.
The first step in Tango’s proposal is to separate out the playing time aspect of WAR:
FanGraphs’ WAR normally is: fWAR = (FIP with adjustments minus baseline) x Playing time, so I used fWAR / (PA-IBB)
Baseball-Reference’s WAR normally is: rWAR = (RA with adjustments minus baseline) x Playing time, so I used rWAR / (PA-IBB)
Then, I only looked at players over the last decade who switched teams in the offseason. Tango does a good job of explaining why this is necessary in his proposal, but essentially, a pitcher’s RA9 in Year X is more likely to be correlated with his RA9 in Year X+1 if he pitches in front of the same defense and same home park. Also, his FIP in Year X is more likely to be correlated with his FIP (or RA9, for that matter) if he pitches in the same home park.
From 2002 to 2011, 207 starting pitchers (min. 200 innings pitched between the two seasons) switched teams in the offseason (~21 starters per season). I regressed these pitchers’ playing time-adjusted fWAR, rWAR and strikeout-to-walk components ((K-BB+HBP-IBB)/(PA-IBB)) in Year X (for example, 2010) against their Year X+1 (2011) RA9, to see which of the three metrics was the best at predicting performance in the subsequent season.
Before I get to the results, I’ll quickly explain the relationship I’d expect to see. There should be an inverse (or negatively sloped) relationship between the predictors (rWAR, fWAR, K/BB) and the outcome (RA9).
For example, we would expect a starter who faces 800 batters and is worth four wins (WAR) to have a lower RA9 in the subsequent season than a starter who faces the same number of batters but is only worth one win. The same can be said for a starter who strikes out 180 batters while walking only 30. We would expect that starter to have a lower RA9 in the subsequent season than a starter who, the same number of batters, only struck out 120 while walking 30.
Results
Here are the scatter plots for the sample for each predictor:
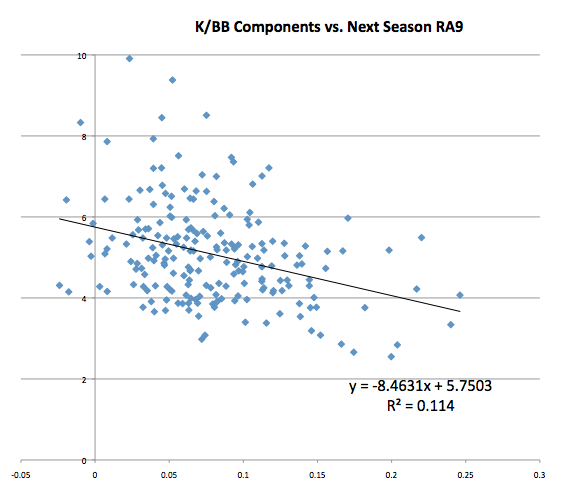
Simple strikeout and walk predictor (*Note: Strikeouts and walks are on a different scale than WAR):
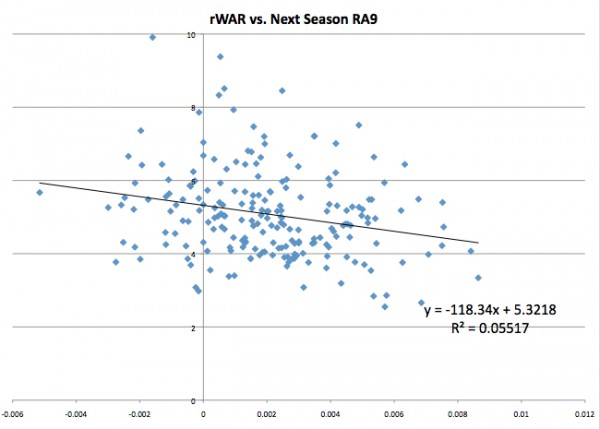
Baseball-Reference’s WAR:
FanGraphs’ WAR:
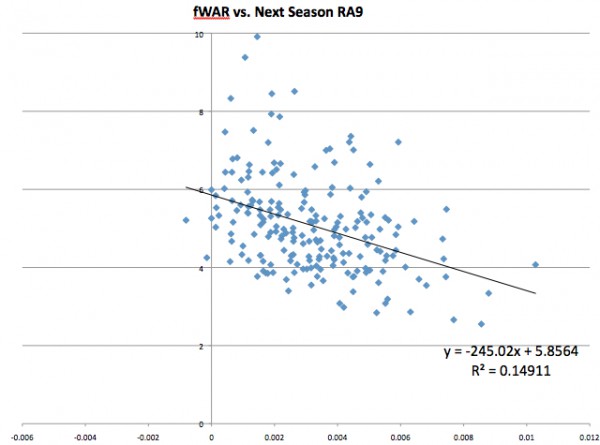
All three of the relationships are negative, as we expected. The actual equations of the regression lines are not as important here as the r^2. A predictor with a higher r^2 accounts for more of the variation in the dependent variable (in this case, RA9), than a predictor with a lower r^2. It is interesting that simply subtracting walks and hit by pitches from strikeouts is a better predictor than an advanced metric like rWAR. FanGraphs’ WAR outstrips the others by a fair margin in terms of r^2 and has almost twice the negative slope as rWAR.
FanGraphs is also the most accurate predictor in terms of root-mean-square error (RMSE):
| Predictor | RMSE |
|---|---|
| fWAR | 1.12 |
| rWAR | 1.18 |
| K/BB | 1.14 |
Comparing three separate single linear regressions and their separate RMSEs is a decent analysis but not a complete one. To test if fWAR really accounted for the most variance in RA9 in a subsequent season, as well as if it was the most significant predictor, I ran a multiple regression using the three predictors together.
Below is an SPSS readout of coefficients from the multiple regression:
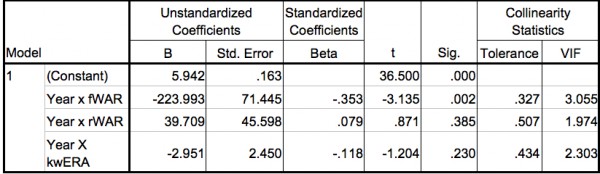
The main columns to look at here are the column titled “Beta” and the one titled “Sig.” The “Beta” column shows the effect each predictor had on the outcome (RA9); rWAR had a near-zero, slightly positive effect, strikeouts and walks (called kwERA) had a small negative effect, and fWAR had a slightly larger negative effect. As I noted earlier, the relationship I expected to see was a negative one, so fWAR having the largest negative effect would lead us to believe that it is the strongest predictor.
The “Sig.” column tells us about the statistical significance of each predictor. Any number below 0.05 would be a statistically significant result. As we can see from the table, fWAR is the only statistically significant predictor of RA9.
I also ran a hierarchical multiple regression where each predictor was added in as a block systematically. Here are the results when rWAR, kwERA and fWAR are added in that order:
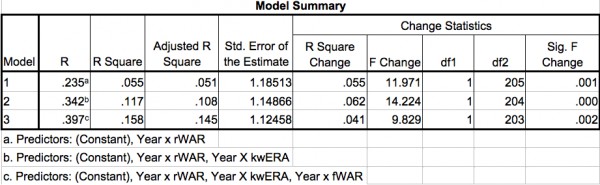
This analysis had some interesting results. Baseball-Reference’s WAR (rWAR) is a significant predictor by itself, but when the strikeout/walk predictor is added in, the r^2 significantly improves, and rWAR is no longer significant. Then when fWAR is entered into the equation, the r^2 improves by a significant amount again, and fWAR is left as the only significant predictor.
Conclusion
Near the conclusion of my article on the correlation between WAR and wins, I noted that WAR does a much better job of describing what has happened than it does of projecting what will happen. I stand by that statement and still really think this statement on our perception of WAR matters:
Single-season WAR should not be used to predict win totals or even WAR in a subsequent season. Single-season WAR also is not supposed to reflect the true talent level of a player, which I think is far and away the largest flaw in the way people interpret the statistic. If WAR did reflect true talent, every player would have the same WAR that perfectly encompassed how much value his talent should bring to his team every single year.
I still think single-season WAR should not be used as an end-all, be-all predictor, but at the same time, in most things—and definitely for major league front offices—predicting the future is more important than describing what has happened. I think projection systems like Oliver, PECOTA, ZIPS, and others, which take many factors (age, past performance, park factors, etc.) into account, are in almost all cases more accurate and more useful than any one single-season metric.
However, this thought brings us back to the original hypothesis, the usefulness of fWAR.
The first part of the hypothesis—rWAR is better at describing what has happened—was not tested in this analysis and still is a point that is up to debate. I think the second part of the hypothesis was answered to some extent with this analysis.
There is a good deal of evidence that backs the idea that fWAR is better than rWAR at telling us what will happen.
I still would argue that WAR, as a metric, is supposed to be describe where wins came from on the field, as opposed to being a reflection of true talent level. But I am only one man, and there are many who still want WAR to be a true-talent metric. Based on fWAR’s predictive/true talent qualities, there is definitely an argument and a place for the use of it.
FanGraphs’ pitching WAR is not a perfect metric. It also is not a perfect predictor. According to this sample, over 85 percent of the variance in RA9 goes unexplained by fWAR, but it still is substantially more predictive than rWAR, which, of course, is important.
References & Resources
I’d like to thank Tom Tango for research assistance, as well as major help in making the model behind this analysis possible.
All statistics come courtesy of FanGraphs and Baseball-Reference.
The first question is nearly impossible to answer, because measures of defensive performance aren’t perfect, and it’s almost impossible to test whether a team’s defense plays better or worse behind certain pitchers.
Its not easy to test, and the methodology may not be perfect, but you probably read this before you declare it “almost impossible”.
http://www.hardballtimes.com/main/article/yet-another-pitching-metric/
If you want you can email me (Tango can give you my email) and I will send you DIRVA for the pitchers you need to test as above.
Peter, I had never seen that article before or heard of DIRVA, very interesting stuff. Would you like me to regress the same 207 pitcher’s fWAR and rWAR in Year X against DIRVA to see which is better at telling us what happened in the season? Not exactly sure I follow…
Glenn – Yes, I thought it might be interesting to test DIRVA as you had tested fWAR and rWAR. I was offering to provide the data for you to do so.
That’d be great if you could send it to me, I’d make it a THT Live Post, my email is