Bringing the Heat

We can better plot how well hitters like Mike Trout fare against fastballs (via Elsie Lin).
Note: This article is based on research done with Dana Sylvan at Hunter College of the City University of New York and presented at the 2014 Joint Statistical Meetings.
Heat maps act as a launch pad for scrutiny and analysis, inform team scouting reports and help hitters identify their weaknesses. There’s just one small problem: traditional heat maps don’t paint an accurate picture of batter abilities.
To design heat maps that better reflect each batter’s true strength across locations we need to incorporate the same kinds of information that we use to create player forecasts – the mean and variance of abilities of a batter’s peers. For simplicity’s sake (meaning ease of explanation or, if I’m being honest, laziness), I’ll focus on building heat maps exclusively for the batting average of right-handed batters against fastballs with the unsubstantiated claim that these methods would likely be comparably effective for lefties as well as for any batting metric (OBP, wOBA, Run Expectancy, etc.) or pitch type.
The map below shows the mean batting average of right-handed batters against fastballs within a 40-inch by 40-inch area in and around the strike zone as seen by the catcher.

Variance gets a bit trickier in two-dimensions–what we need is a covariance matrix. To estimate this matrix, we split the strike zone into a 6 x 6 grid and looked at the covariance in batting averages between each pair of locations as a function of the distance between those two locations.
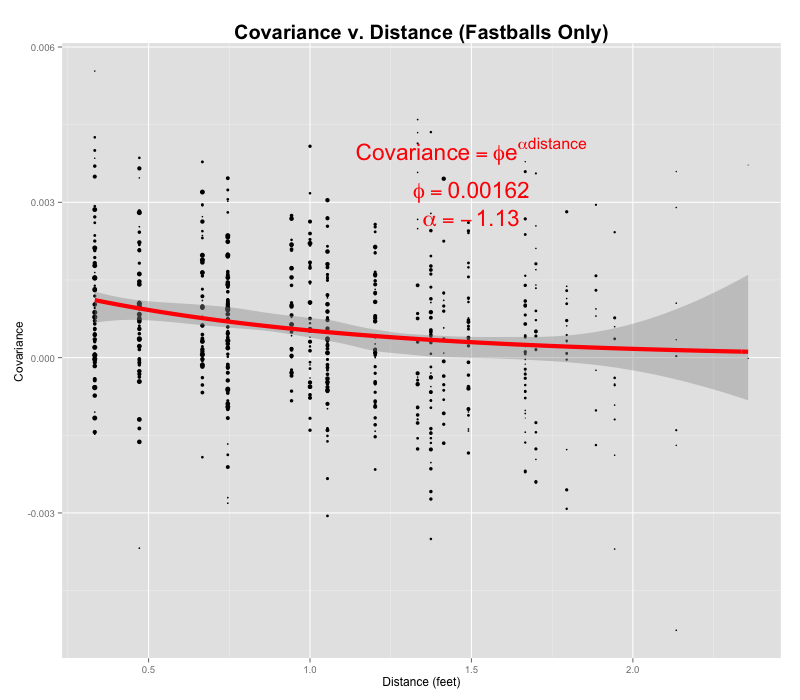
The gray area shows the 95 percent confidence interval for a LOESS smoothing line (essentially a moving average) through the data. The red line shows the best-fit exponential curve. If this line were perfectly flat we could stop right here and never look at another heat map; a flat line would indicate that there’s no such thing as a hot zone. Our line isn’t flat however, so there’s more work to be done.
The parameters of this best-fit line are actually interpretable. The square root of ϕ, 0.040, gives the standard deviation of batting ability at any given location. In other words, if the typical batter hits .250 against pitches on the lower-inside corner, we’d expect roughly two-thirds of batters to have a true ability between .210 and .290 at that location. α tells us the extent to which covariance in batting ability decays with distance–this best fit line estimates that batting ability has a half-life of about 7.5 inches. If we’re estimating Mike Trout’s talent level against pitches belt-high on inside edge of the plate, the result of one such pitch is twice as relevant as the result of a pitch down the middle (roughly 7.5 inches away) and four times as relevant as the outcome of an outside pitch 15 inches away.
Imaginary Batters
We can now model a batter’s spatial ability in the same way that a Strat-o-Matic card or Diamond Mind event table models a batter’s overall ability. The maps below show nine imaginary (but, we hope, sufficiently realistic) batters created using the league average map and a covariance matrix based on our exponential decay curve.
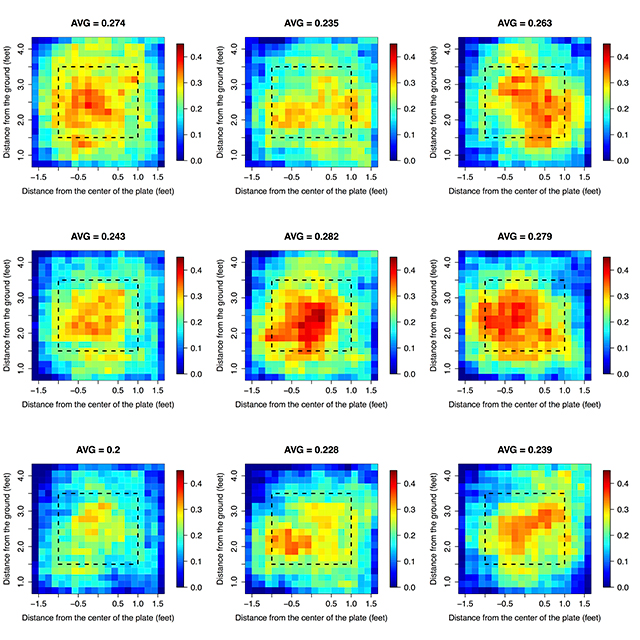
Some of these batters are simply better hitters than others. The imaginary batter in the center square would be a true-talent 0.282 hitter if pitted against a typical distribution of pitch locations, whereas the batter in the lower left would hit only .200 in the long-term. The exponential decay curve estimated above creates a distribution of batters with a standard deviation of 22 points in true-talent batting average. This roughly matches the distribution of true talent in batting average estimated by Steamer and provides something of a sanity check on our imaginary batter population. Notice that while these hitters have different hot and cold zones, none of them does their best work outside of the strike zone, and they all hit at least respectably on pitches down the heart of the plate.
So, what in the world do you do with a boatload of imaginary batters?
Throwing Imaginary Pitches
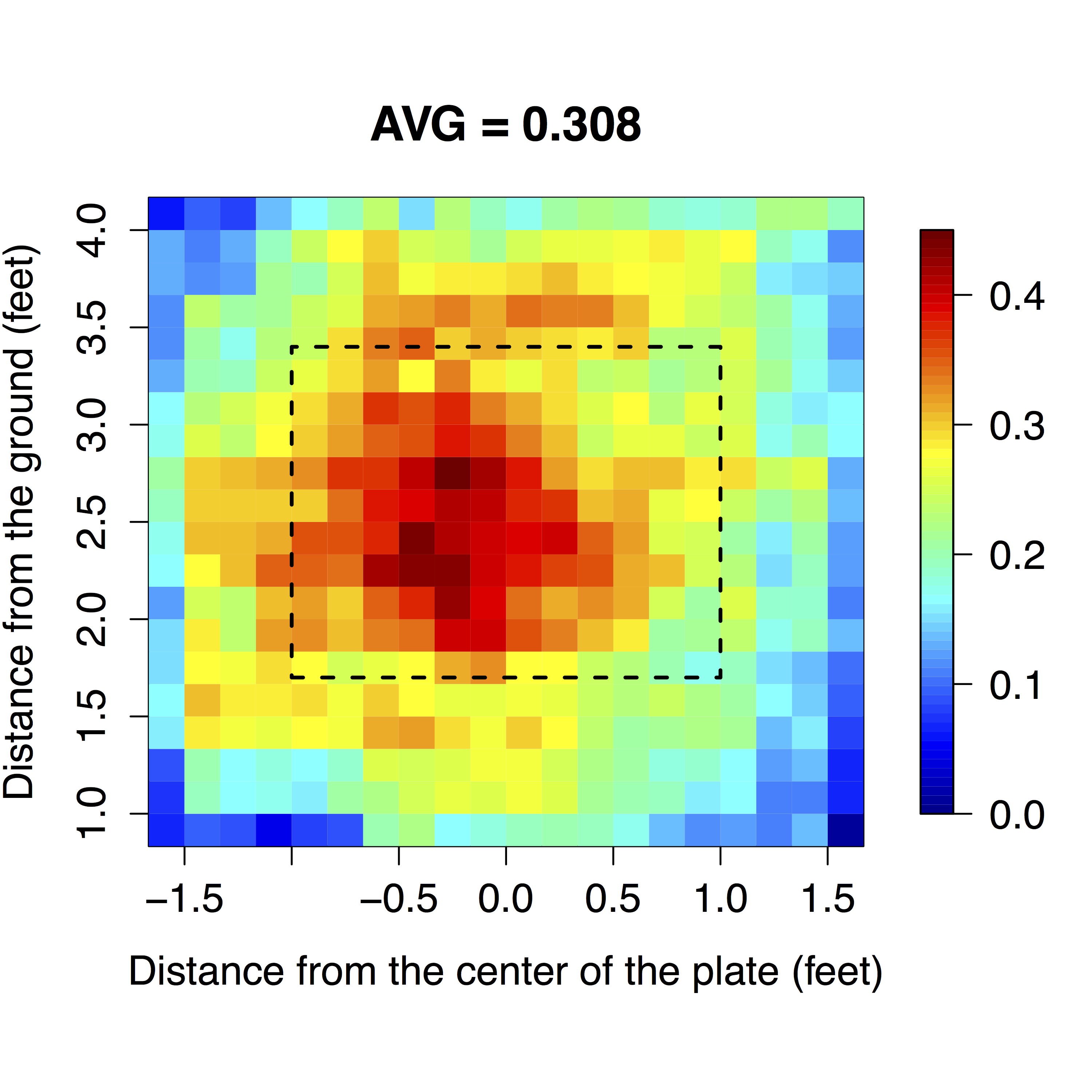 Yes, the answer was all too obvious. We can take an imaginary batter, for instance, the one shown on the right, and let him play a series of imaginary seasons. In each season, we’ll give him 400 at-bats that ended on fastballs. To determine the locations of the imaginary pitches, I sampled from the locations of actual end of the at-bat fastballs from the past two seasons. Our batter’s chance of getting a hit on each pitch is determined by his true talent heat map. We then mapped the results of each season using a traditional heat map to gauge how accurately these maps represent our batter’s true ability across locations.
Yes, the answer was all too obvious. We can take an imaginary batter, for instance, the one shown on the right, and let him play a series of imaginary seasons. In each season, we’ll give him 400 at-bats that ended on fastballs. To determine the locations of the imaginary pitches, I sampled from the locations of actual end of the at-bat fastballs from the past two seasons. Our batter’s chance of getting a hit on each pitch is determined by his true talent heat map. We then mapped the results of each season using a traditional heat map to gauge how accurately these maps represent our batter’s true ability across locations.
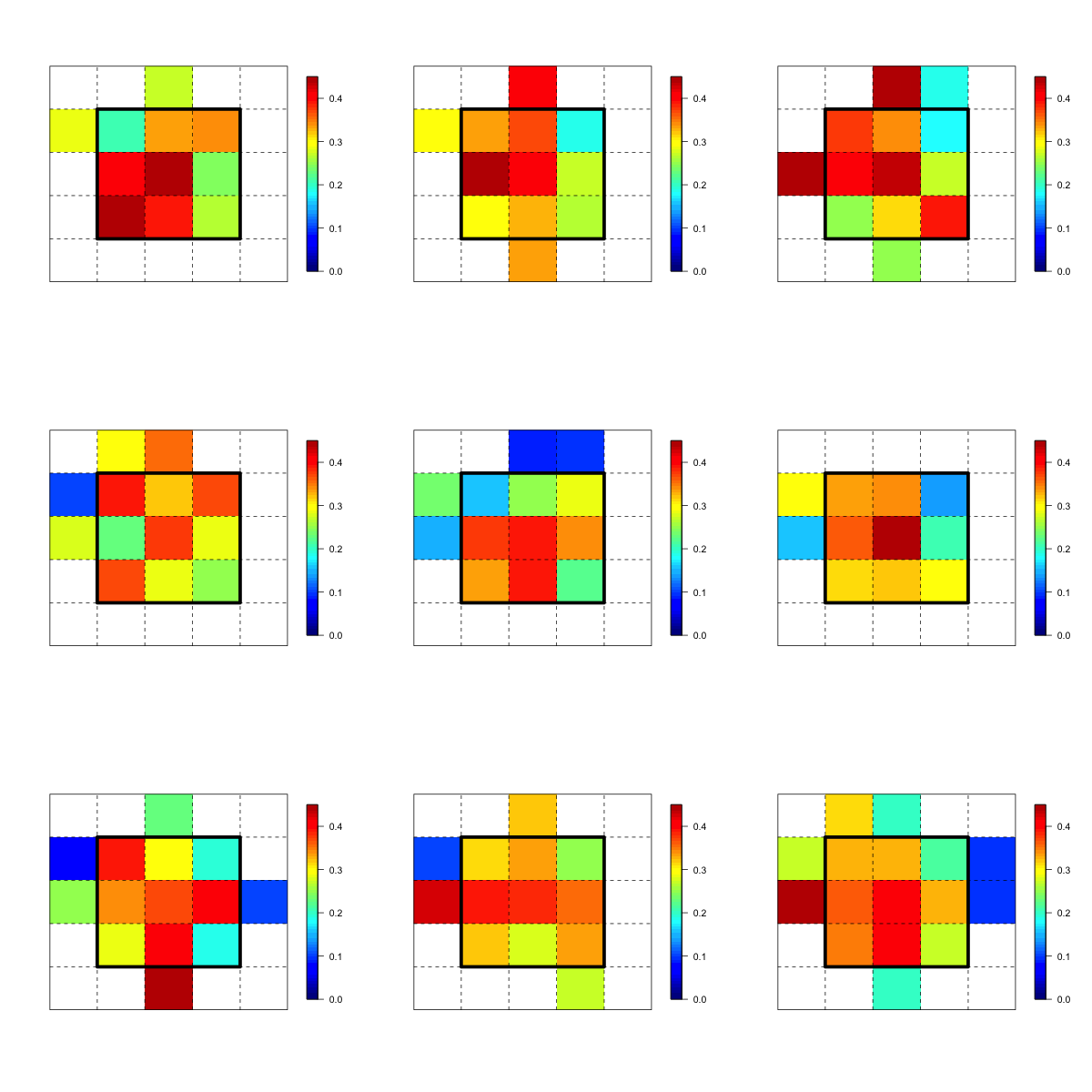
The maps above show the results of nine simulated seasons with the color of each bin representing how well our batter hit in that zone in the season in question (zones that saw fewer than 10 pitches in a given season are left blank). Ideally, these maps would resemble each other as well as our batter’s true talent map, but they appear to do neither. Worse, they make bold predictions about hot and cold zones that have little basis in reality.
To settle on a better procedure for building heat maps, we’ll first identify a set of worthy (and not so worthy) competitors and then, after a series of simulations, quantify how closely each competitor’s heat maps match reality.
The Competitors
Fair warning: This section gets a little dry, so feel free to skip ahead to where it says “In Short.”

- The Sample Average: Let’s start with the simplest model. This system takes a batter’s average across locations and uses that to estimate his ability anywhere and everywhere.
- The 5 x 5 Grid (the traditional method): These maps split the area in and around the strike zone into a grid and estimate the batter’s ability within each zone as his observed average in that zone.
- League Average: This method completely ignores each batter’s individual results and estimates that he hits exactly as well in each location as the average batter does in that location.
- Adjusted League Average: This method starts by taking a batter’s observed average across locations and regresses it to the overall league average to estimate the overall quality of the batter. Then it adjusts the League Average map up or down based on the overall quality of the batter. Note that it pays no attention to the spatial components of our batter’s observed ability.
- Ordinary Kriging: This method estimates a batter’s ability at any location based on a weighted average of his results at other locations with nearby locations receiving more weight. The relative weights are determined by a covariance matrix estimated based on the batter’s observed results.
- General Additive Model (GAM): This builds a non-parametric model of batting ability as a function of an interaction between horizontal and vertical locations with the number of smoothing parameters determined by cross-validation.
- Kriging Residuals with Known Covariance Matrix: This is a three step plan we devised in order to map a hitter’s results in light of the what we know about the league (namely, the league mean and covariance function. First, we determined how much better or worse this batter performed at each location than we might have expected based on a simple model that merely adjusted the League Heat Map (competitor #3) uniformly up or down based on his observed batting average. These differences (between the predictions of this simpler model and actual results of his at bats) are the residuals of the simple model. Next, we performed Kriging on these residuals using the covariance function we estimated from the earlier (the red exponential decay curve shown on the covariance versus distance graph above). Finally, the map produced by Kriging residuals was added to the Adjusted League Average Map (competitor #4) to estimate the batter’s ability at each location.
In short: The 5×5 grid, Ordinary Kriging, and GAM models all use information about where the batter in question has hit well and where he has hit poorly. They don’t use what we know about the population of batters (the league average and the covariance matrix). League Average and League Average Adjusted use what we know about the population but don’t use information about a batter’s individual spatial results. The Sample Average uses neither league information nor individual spatial results. Kriging Residuals uses the individual’s spatial results along with the population mean and covariance matrix.
The Results
We simulated large numbers of seasons/careers with 200, 400, 1,200 and 2,000 at-bats using a different imaginary batter in each simulation–1,000 simulations for “seasons” with 200 and 400 at-bats and 500 simulations of “careers” or 1,200 and 2,000 at-bats.
After each simulation, the models were used to estimate the batter’s true ability on an 80 x 80 grid of locations in and around the strike zone. A system’s errors are the differences between its estimate and the batter’s true talent map at each location. These errors were weighted by the proportion of actual major league pitches at that location.
| Weighted Root Mean Square Error in Batting Average Maps |
|---|
| At-Bats | ||||
|---|---|---|---|---|
| System | 200 | 400 | 1,200 | 2,000 |
| Kriging Residuals | 36.7 | 35.2 | 32.9 | 31.6 |
| Sample Average | 77.8 | 80.8 | 77.1 | 75.4 |
| 5×5 grid | 169.9 | 132.2 | 85.4 | 70.9 |
| League Map | 38.8 | 38.6 | 39.1 | 39.6 |
| Adjusted League Map | 37.0 | 35.8 | 34.5 | 34.4 |
| Ordinary Kriging | 79.6 | 65.0 | 48.0 | 41.9 |
| GAM | 83.8 | 65.2 | 45.7 | 39.6 |
In each of the four lengths of simulations, Kriging Residuals outperformed all of the other models. While its advantage over the Adjusted League Map was small for 200 at-bat simulations it performed increasingly well with more information. None of the systems that rely on an individual batter’s results without consideration of the population do as well as the Adjusted League Map (which ignores an individual’s spatial information altogether) even after 2,000 at-bats. It took 2,000 at-bats for the 5×5 grid to outperform even the Sample Average and 5×5 grids performed particularly poorly after 200 and 400 at-bat spans.
Another way to gauge the effectiveness of the Kriging Residuals maps is to look at the percentage of simulations in which its heat map was closer to the truth than each of its competitors’ heat maps.
| Winning Percentage of Kriging Residuals |
|---|
| At-Bats | ||||
|---|---|---|---|---|
| System | 200 | 400 | 1,200 | 2,000 |
| Sample Average | 99.7 | 100.0 | 100.0 | 100.0 |
| 5×5 grid | 100.0 | 100.0 | 100.0 | 100.0 |
| League Map | 64.5 | 71.9 | 87.8 | 93.6 |
| Adjusted League Map | 72.6 | 81.3 | 91.4 | 96.0 |
| Ordinary Kriging | 99.7 | 99.4 | 97.4 | 95.0 |
| GAM | 99.6 | 98.3 | 96.2 | 91.2 |
Kriging Residuals outperformed the Adjusted League Map 72.6 percent of the time after 200 at-bats (although the two predictions would be quite close after with this little data) and 93.6 percent of the time after 2,000 at-bats. It also outperformed the 5×5 grids in every simulation we ran at every number of at bats.
There’s just one problem…
The heat maps produced by Kriging Residuals (shown below) look remarkably alike–even after zeroing in on the area inside the strike zone to highlight the differences–and each of these maps strongly resembles the League Average Map. While it’s true that we can see that Mike Trout hits low pitches better than Derek Jeter does, the differences between these maps are rather subtle relative to the chasm between how these batters hit in the center of the strike zone and how they hit on the corners.
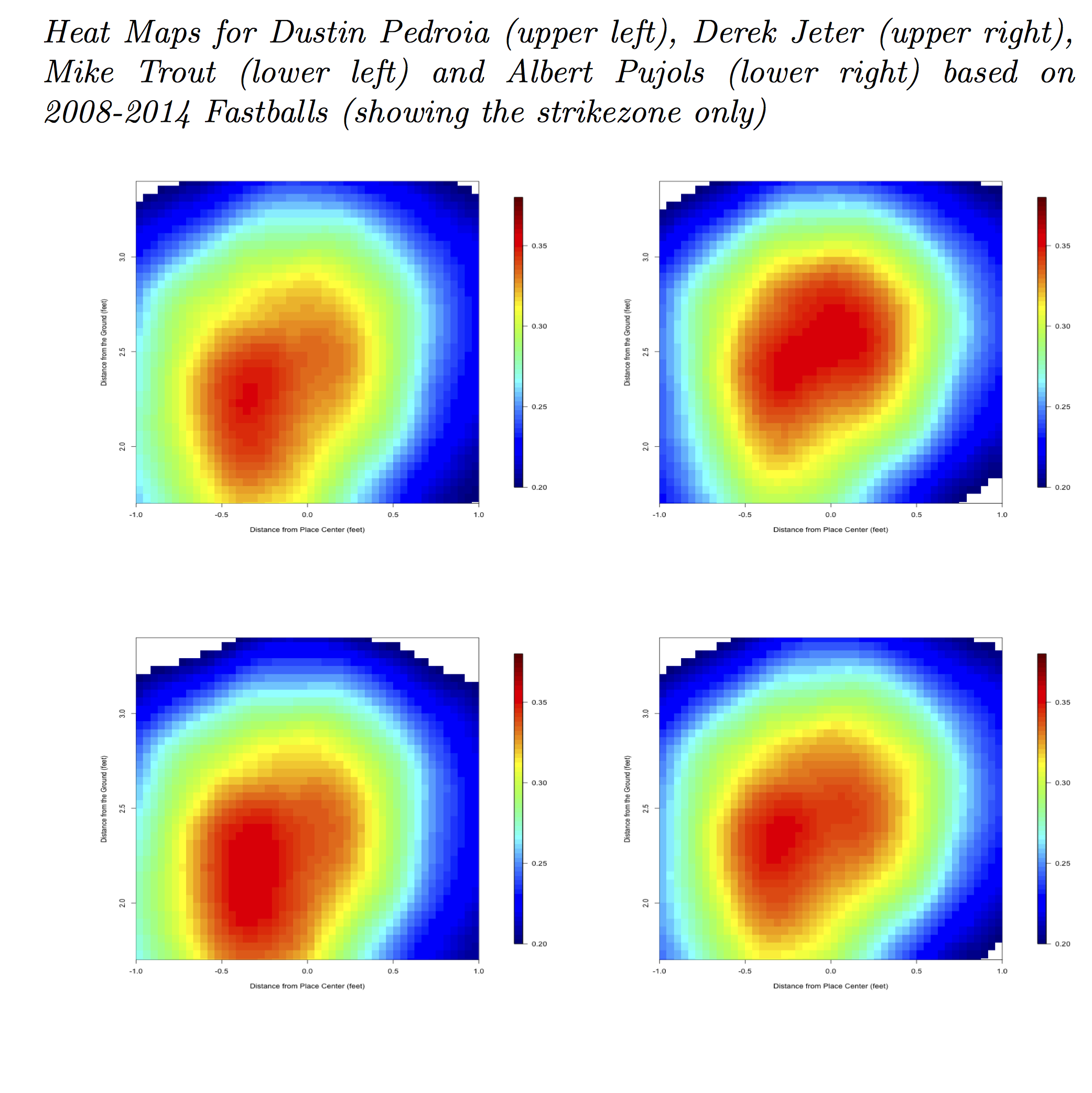
Rescuing the Heat Map
What we’re most interested in, perhaps, is each batter’s spatial peculiarities. We can rescue the heat map by looking exclusively at the spatial residuals–the difference between the Kriging Residuals prediction, which incorporates individual spatial information, and the Adjusted League Map which does not. Thanks to running a large number of simulations and noting the errors, it’s also possible to model the uncertainty in these maps.
The following shows the 25th, 40th, 50th, 60th and 75th percentile estimates of Derek Jeter’s actual ability in each location above or below his Adjusted League Map. The 50th percentile map is necessarily centered on zero.
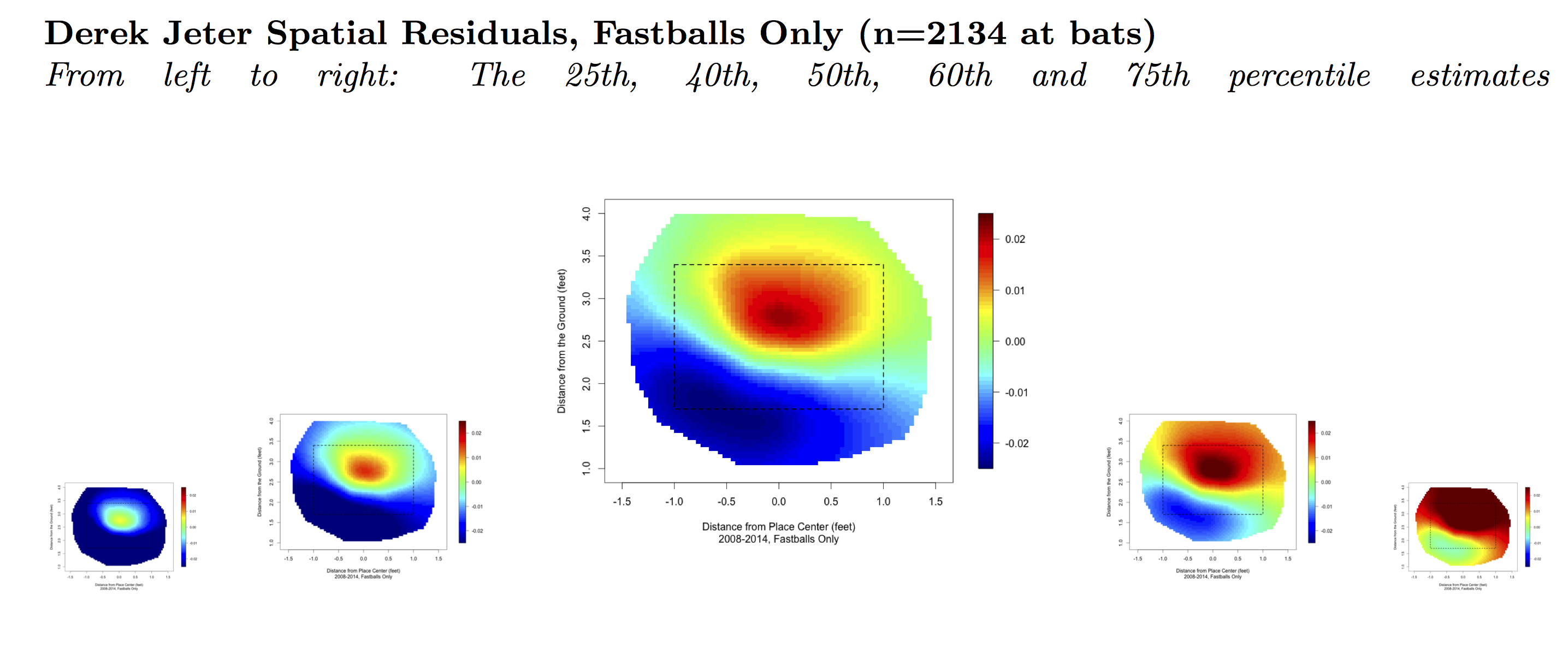
Jeter’s 50th percentile map estimates that he is roughly 20 points better than we might otherwise expect (based on his estimated overall talent) on pitches up in the strike zone and roughly 20 points worse than we might expect on pitches down and in.
In the heat maps that follow you can see Trout’s strength down and in, Pujols’ hot zone up and away, and Pedroia’s ability to turn on pitches inside and up in the strike zone. Also note that Trout’s map shows less definition than the other maps shown here due to his shorter history.
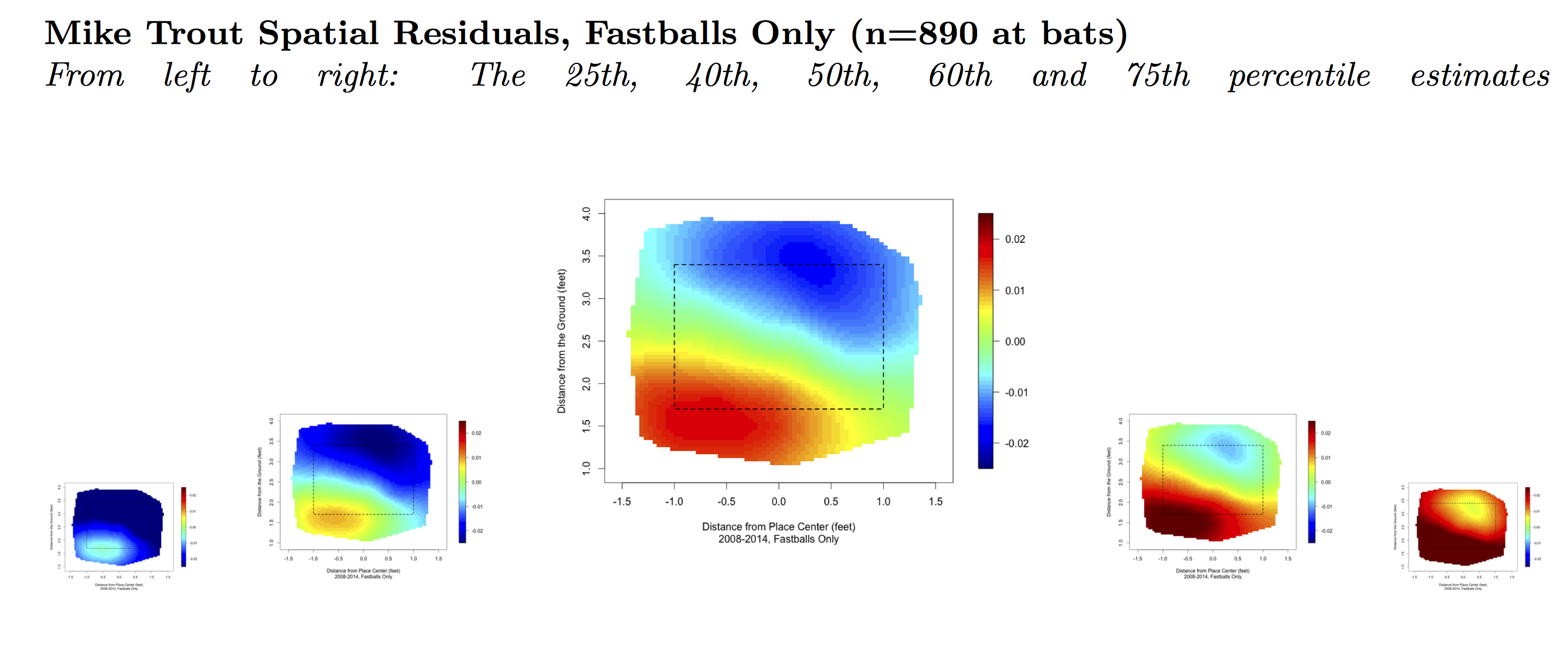
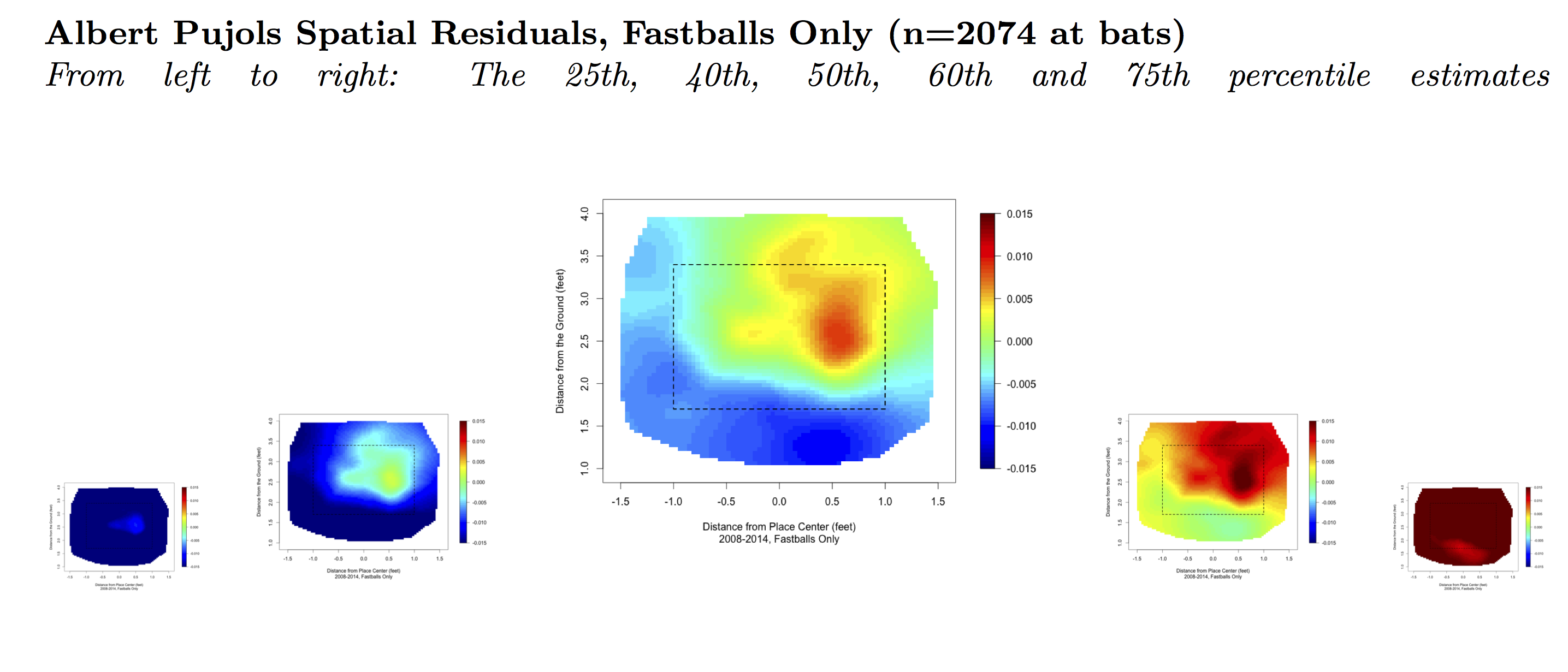
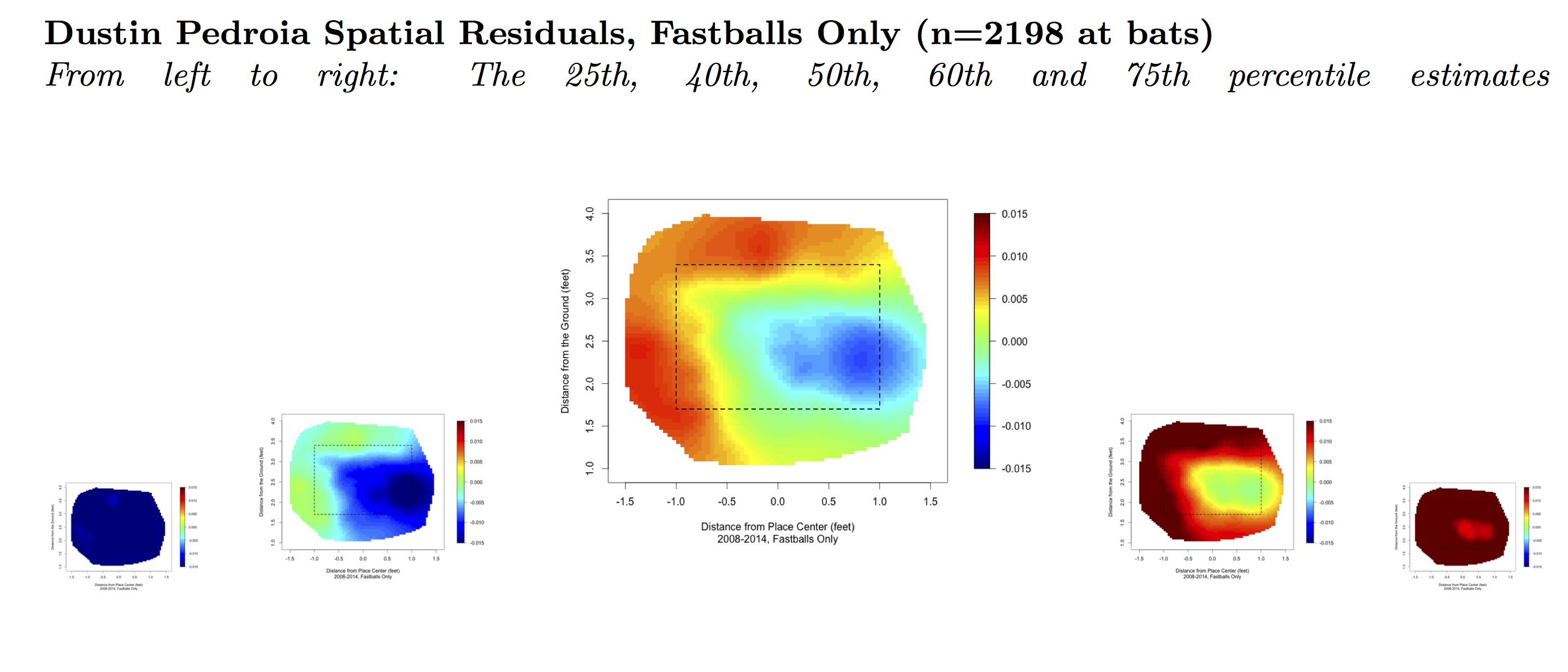
These heat maps and the success of Kriging Residuals suggest that it’s possible to create heat maps that sensibly inform us about a batter’s relative strengths. To do so, we must see his results in the light that our knowledge of his peers provides.
References & Resources
- Baumer, B. and Draghicescu, D. (2010). Mapping batter ability in baseball by using spatial statistics techniques. JSM Proceedings, Section on Graphical Statistics, American Statistical Association, 3811-3822.
- Fast, M. (2011). Can We Predict Hot and Cold Zones for Hitters?
- Furrer, R., Nychka, D. and Sain, S. (2012). fields: Tools for spatial data. R package version 6.7.
- Mills, B. (2011). Maximizing Sabermetric Visual Content: Smooth Comparisons and Leveraging Color
- Stein, M. L. (1999). Interpolation of Spatial Data: Some Theory for Kriging. Springer.
Nice work.
so well done. Thanks, Jared.
Thanks, guys!
But this area of study is not telling. In fact the numbers basically show that there is none and anything you see is basically a function of the absurdly small samples you are dealing with here.