Getting out of the injury zone, part one
Over the last decade, we’ve seen these insane statistics with regard to arm-related injuries to pitchers:
{exp:list_maker}Serious elbow injuries (90+ days on the disabled list) were responsible for 41,997 days missed, with 277 individual players affected.
Serious shoulder injuries (90+ days on the disabled list) were responsible for 39,696 days missed, with 264 individual players affected. {/exp:list_maker}
Just consider how much this costs teams. If you just take the average salary for each of the years and pro-rate it out per game… yikes!
There’s no doubt that every major league wants to improve in this area. If an organization can meaningfully reduce disabled list expenses, it not only saves money by not calling up new players while paying the salary of players on the disabled list, but adds a significant amount of expected wins to its season totals (since replacement players for injured players are almost always worse than the players going on the DL). Billy Beane said at Internet Week in New York:
“The biggest indicator now—for a sports team—of whether you’re going to be successful or not is whether or not you stay healthy. The health of baseball players, the health of football players, is going to be a better predictor of a team’s performance. And the guy who gets his arms around that is going to be the wealthiest man in the world.”
Wealthiest man in the world, you say? Well, I’ll throw my hat in the ring. Anything for a good cause, you know…
What we know so far
While we don’t yet have a good grasp of what causes arm-related injuries, it’s not for lack of trying. The American Sports Medicine Institute (ASMI) has been doing tons of research on the topic of safety and health for baseball pitchers for decades now. However, ASMI is quick to point out that its guidelines (this post on the ASMI messageboards has some data; the thread itself is a fun ride involving Dr. Marshall’s pitchers if that’s your cup of tea) are not predictive, and it is yet to be demonstrated that there is a specific cause-and-effect relationship between certain kinematics/kinetics in the pitching delivery (so-called “pitching mechanics”) and chance of injury.
Pseudo-explanations of The Inverted W sound good (and even have some scientific basis behind them), but they are not rigorous analyses of the field in question. (Isn’t an inverted W just an M?)
Josh Kalk looked into PITCHf/x data in an article that should be well-known to everyone: The injury zone. This article is one of his last public works before he was snapped up by the Tampa Bay Rays, and I cannot overstate how influential it has been when it came to my research over the last two years. I followed up Kalk’s post with an inconclusive regression analysis of PITCHf/x data back in 2011, and others have done the same.
Since then, I’ve built a biomechanics lab in Seattle:

I learned it was a giant pain in the rear to actually collect data on a large-scale basis—finding research subjects while working a full-time job and tending to a family isn’t easy! Still, I’ve made some progress, and a discussion on applied biomechanics and kinesiology will come later in this series of articles once we get to player development and scouting. The focus of today’s article is approaches using stats, math and computer science to get an insight on where injuries come from— specifically the use of machine learning.
Why machine learning?
A famous computer scientist once said: When in doubt, use brute force. Machine learning (ML) is a great tool for these types of analyses, because ML is most effective when it comes to complex situations where we have a defined outcome (injuries to the arm due to throwing a baseball). An approach using frequentist inference—standard “statistics” as you know them— tends to be a poor fit in these situations. ML allows us to let a computer self-learn about a particular data set where humans cannot adequately write a program to understand the problem.
Machine learning is also very well-suited when it comes to supervised learning, which describes the problem we’re trying to solve in baseball. We have a vast array of data that show when pitchers go on the disabled list, for what reasons, and what they were doing precisely before they were injured (PITCHf/x data, game logs, etc). By feeding a neural network a set of input data (PITCHf/x variables, in this case) and a defined output (binary—injured vs. not injured, in this pilot model), you can theoretically tease out the relationship among many inputs and the one output you train the network with. (A neural network can have multiple outputs, for the record.)
Preparing the data
In Josh Kalk’s article, The injury zone, he used the following criteria for admission:
- Pitchers who missed at least one start due to arm-related injury
- The pitcher was a starter, not a reliever
- PITCHf/x variables of release point (x0, z0), horizontal/vertical movement (relx, relz), and velocity (velo)
- A standard deviation (STDDEV) model that accounted for pitch types and individual pitchers
- A large number of non-injured pitchers for a background sample
- The last 10 pitches a pitcher threw before going on the DL

I modified the approach slightly:
- Substituted variance of the vertical release point (VARrelz) for raw vertical release point (z0), as my previous statistical research showed this could be a relevant marker
- Did not limit the pitches to the last 10 thrown, used 100 percent of all pitches thrown in both training and test data. Used the last game thrown before a DL appearance for injured pitchers, used a random date in the regular season for healthy pitchers
I did keep the standard deviation approach—Josh explained the STDDEV approach very well in his article:
To normalize this process, we will be comparing these values in terms of standard deviation. This is a rather complicated idea so let me give you an example. If Joe Pitcher’s average fastball is 90 mph with a standard deviation of 1.5 mph and he throws a fastball at 87 mph, that fastball is -2 standard deviations away from his average. Pitches are always compared to the same type pitch for the average (fastballs to fastballs, sliders to sliders, etc.). This pitch, plus nine others, will be averaged for each of the variables we are interested in. This way we can properly compare a fastball thrown by Jamie Moyer and one thrown by Ubaldo Jimenez.
I took two years worth of pitchers and PITCHf/x data and applied a release point adjustment algorithm (sample data came from former THT writer Max Marchi many years ago, thanks Max!) to adjust for park effects. I didn’t make any changes to velocity, though a more rigorous approach would have done so and perhaps also adjusted for seasonal variability.
After randomly selecting 75 percent of the data to serve as the training data set, I was ready to construct and train a neural network.
Building the neural network
Neural networks (NNs) sound exceedingly confusing, but in reality aren’t that tough to understand from a basic perspective.
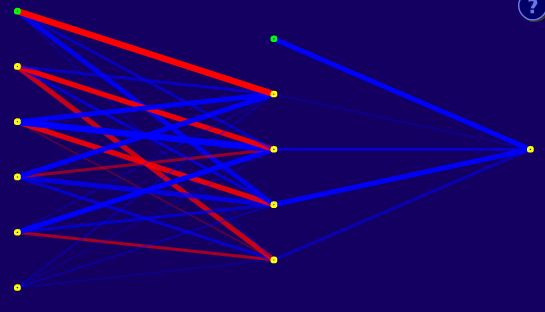
The neural network used for this study: five input neurons (+1 bias), four hidden neurons (+1 bias), one output neuron
You have three layers—input, hidden, and output—that make up a neural network. Each neuron in the input layer is a variable that you’re hoping will help make a prediction for the neurons in the output layer, and in between them lies the hidden layer, which transforms data. In this case, my model uses resilient backpropagation (RPROP). In backpropagation learning techniques, you are essentially feeding forward a guess, which is compared to the true outcome (the reason it’s called supervised learning). Then the error is fed back through the network, where the hidden layer tweaks the weights and the cycle continues until the error reaches a manually set threshold, or the network cannot be improved upon. The “error” is usually measured as root mean square error, or RMSE (you know this acronym well if you’ve ever read an article by Colin Wyers).
(For the math/CS nerds out there, I used the sigmoid function for my activation functions.)
“But how many hidden layer neurons should you use, Kyle,” asked no one ever. “And could you use multiple hidden layers,” chimed in literally nobody. There’s no deterministic rule for the first question; most people tend to use a formula like ROUNDUP(2/3*inputs+outputs) or SQRT(inputs*outputs). I generally fall in the first camp as a starting point, but again, there’s no rule. Secondly, yes, you can use multiple hidden layers, but no practical problem in the world requires more than two hidden layers, and the vast majority of problems can be solved with a single hidden layer. The explanation behind this is beyond my understanding and is also not germane to the discussion, so I’ll skip that.
The results of the model
I trained the network using the 75 percent data set, and once it was built, I passed in the remaining 25 per cent as a test case. The results were rather shocking.
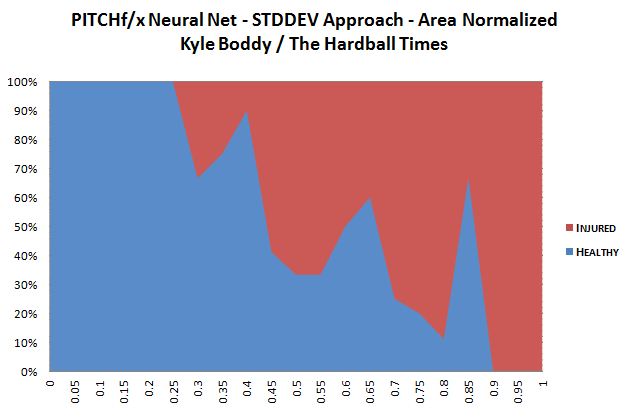
(Velocity was the most important variable, followed by vertical movement and vertical release point variability, then horizontal movement. Horizontal release point was almost all noise.)
As Josh did in his histogram, I normalized the data so the total area would be 1 to better see the separation and scaled the output weights for the same reason as well (in reality, the weights ranged from approximately 0.10 to 0.85).
If you arbitrarily placed a cut at the 0.45 weight level, the remaining normalized injured population is more than twice that of the normalized healthy population. In Josh’s model, he had a 3:1 difference with an cut at the signal at 0.5. Put another way, if you did a strict classification model on the non-normalized data (using original weights), the neural network and test case in question would “guess right” more than 80 percent of the time on whether a pitcher would be landing on the disabled list after his start.
However, Josh said something I disagree with:
If a pitcher enters this zone there is about a one in three chance for him to end up on the DL instead of making his next scheduled start.
Josh’s full sample didn’t corroborate this statement:
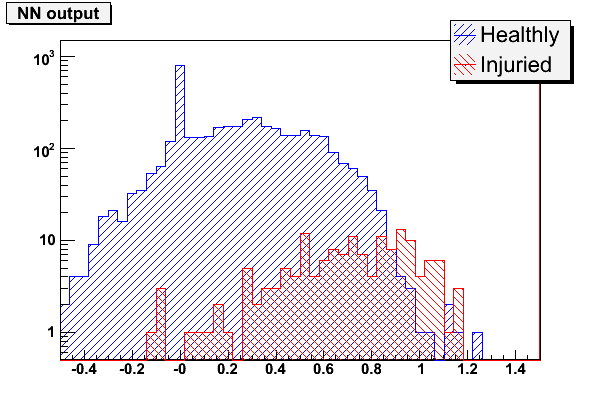
My model is much the same way:
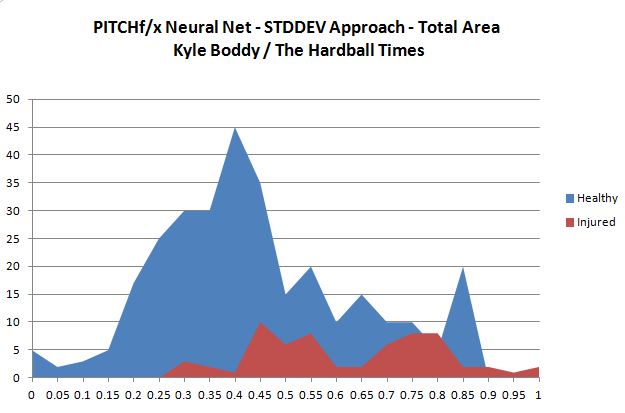
Weights normalized, population not normalized
The reason for this is fairly simple: More pitchers than not stay healthy throughout a given year! You don’t get to pick a matched group of 50/50 when using a neural network for real-time classification; you get the whole population. So, if you used this network to predict who would be injured, you’d be pulling healthy starters way more often than you’d be pulling injured starters, even if on a percentage basis you’d be right. However, that doesn’t invalidate the model. There are two major ways this model could be used to improve the health of pitchers:
Applications of the neural network
By deploying a neural network like the one in this article, you could identify pitchers who were very unlikely to be injured. Look at the left side of the graph— nearly no injured pitchers in the test case fell on that side! You could be very confident in sending your pitcher back out for 110+ pitches if you knew he habitually fell on the left side.
Additionally, if you had a pitcher who was consistently in the “injury zone,” you would want to treat him with additional care in the training room. This neural network is not meant to be used as a catch-all tool, but rather as a single piece of a multi-layered approach to combat injuries on the big league roster.
Suggested improvements, and a look to the future
As described above, the model could have used cleaner data (particularly with regard to adjusted velocities), and perhaps adding an output neuron with the severity of the injury would have provided some interesting insight. Additional inputs like age, time of service, pitch mix, sequencing, and so forth could also be added for further improvement.
However, the biggest improvement that I foresee would be if an organization captured real-time kinematic (and possibly kinetic) data from its pitchers while they threw from a mound. This could be done in one of two ways:
{exp:list_maker}Simple: Have high-speed cameras in fixed positions record a pitcher from the side and front to capture planar kinematics, and use these markers in a neural network and/or regression analysis
Complex: Install a true three-dimensional analysis setup in your stadium where multiple high-speed cameras were calibrated using a control object (much like the one you see me standing in at the beginning of this article) to capture precise kinematics and kinetics of a pitcher in real time. Then use that information with a variety of machine learning and traditional statistical approaches to help mitigate injuries
{/exp:list_maker}
An example of simple motion capture for planar kinematics (Driveline Baseball)

An example of complex three-dimensional motion capture for kinematics/kinetics (Driveline Biomechanics Research)
With “mechanical” data, you could tell your player development staff how to treat athletes in the training room, or provide your scouts with additional information for trade targets.
ASMI does lab-based studies using markers and a Vicon system, but there are major problems with this concept: The Vicon system is very cost-prohibitive and lab-based data may not be representative of real-world performance. Few pitchers have gone to ASMI and thrown over 90 mph with the markers on, in a lab setting, in sneakers, not throwing to a catcher. While it’s undeniable that a field biomechanics collection setup would have a higher collection error, the difference between lab data and real competition data is likely to be enormous! There is no guarantee that lab data scales in a linear fashion to real world performances.
Wrapping up
In part two of this series, we’ll investigate more applications of this neural network data as well as how an organization could further unify their departments to make data-driven decisions. Player development and scouting are the two areas that have yet to have their major revolution—mostly because it seems too difficult to quantify that type of data. My hope with this series of articles is to help put that unfounded rumor to rest.
My library doesn’t support the LOO classification test, it appears, but I can look into it!
Can you clarify what you mean by input/output parameters? I’m not sure I understand what it is you want me to… clarify.
You fed the network a vector of input parameters – what were they? Can you give an example?
Was the network’s task binary classification? (Injured vs. Not Injured?)
I used the same inputs as Josh with one change, here were the results:
(Velocity was the most important variable, followed by vertical movement and vertical release point variability, then horizontal movement. Horizontal release point was almost all noise.)
That sentence is right below the normalized histogram.
Binary classification on injured/not injured, yes.
Would you be open to sharing your training data? I’m still trying to wrap my head around what the network is actually keying on to learn the difference between an injured and an uninjured pitcher.
Possibly in the future, but I’m not ready to release the data as open source. The PITCHf/x data can be derived through the methods Josh and I pointed out, however.
I’m curious to know the results from something like a LOO (Leave One Out) classification test (fairly common), where you train the network with N-1 samples and test on the Nth sample.
Also, can you specify exactly what the input parameters and output parameters of the network were?
Thanks for the cool research!
Well, I guess I’ll recreate the dataset then. =(
What package are you using to train your network?
I first tried to use a PHP library, but had some problems with it – I eventually settled on using Fast Artificial Neural Network (FANN) and wrote C code to run it. It works well enough; kinda weird, but easier to use than WEKA or other comparable libraries.
Oh! I totally forgot. You could consider using Google Prediction!
https://developers.google.com/prediction/
Definitely something I want to consider in the near future.
Thanks for the awesome article. Could you please explain the charts a bit more? What are the axes? Have you generated an ROC curve for your classifier (it looks like the charts are kind of showing similar info to what an ROC curve would show, but I can’t be sure without seeing the axis labels). Also, did you consider any other classification algorithms instead of neural networks (SVM, decision trees, etc.)?
Regarding Weka, the best thing about it is that it has so many techniques. The worst thing about it is that it has so many techniques.
testing fucking testing.