Getting closer to park adjustments for PITCHf/x
Josh Kalk had a very sophisticated method for adjusting PITCHf/x for differences between ballparks, even accounting for atmospheric conditions. In contrast, my approach has been rather crude and, frankly, incomplete. Good enough to share! To introduce my crude and evolving methodology, I figured I should start by defining the problem.
What’s the problem?
PITCHf/x data, such as pitch speed and spin movement, are based on nine inputs—location, velocity and acceleration, each in three coordinates (x,y and z, corresponding to side-to-side, rubber-to-plate and ground-to-sky respectively). Two cameras are used to capture the ball’s flight; estimate those initial nine inputs and calculate the ball’s flight characteristics. Once we know what those are (speed, spin etc.) we can classify the pitch. Gameday does it in real time, which is amazing. Not 100 percent accurate, but getting better all the time. Still, post-hoc classifications are usually more accurate, and can be used by MLBAM to tweak its own classifications.
While the values produced by MLBAM’s Gameday are estimates of the pitch location and movement, they happen to be incredibly accurate estimates. Still, there is a problem—the cameras are almost never in the same location from park-to-park. This limits our ability to compare outings by the same pitcher, often forcing researchers to narrow down to a single park to dodge the noise created by combining parks. This is no silver bullet, as parks have been adjusted over the years and even during games. Still, release points, movement and even speed can vary within and between parks such that the same pitcher throwing the same way may look radically different to two different PITCHf/x configurations.
What I think can be achieved
This is really a matter of opinion, but I don’t think the goal of post-hoc data correction is worth the effort. The best bet is to catalog the issues and let Sportvision and MLBAM do what they can to adjust the systems to correct issues going forward. The benefits of re-running everything from 2006 on to correct for the issues may be enticing, but the effort could be cost prohibitive. Which takes me full circle, to contradict the first sentence of this paragraph. If they can’t do it, we should. I just believe they’ll do a better job at fixing system issues while layman like myself will risk “cleaning” variance out of the data that’s actually meaningful. Still, I’ll hedge and give it a whirl.
To balance where I think the work should be done (and by whom) and what I feel is achievable in my own domain, I’ve set out two goals. If I had a third goal, it would be use “I” less in my next article.
- Normalize each park to itself
- improves pitch classification
- provides more opportunities for “safe” game-to-game comparisons
- can be risky—there can still be meaningful variance based, for example, on date/weather/time
- Normalize all parks to a standard park, or something to that effect
- allows for park independent comparisons
So, my goal is to focus on classification first and more sophisticated comparisons later. Why?
I think solid park-by-park, game-by-game classifications can be very useful inputs analyzing the differences between parks. But my own motivations are more practical.
Classifying a reliever is tough. I can’t always say what’s what when there are only 12 pitches from a single appearance, or fewer, even if I already have other data on a pitcher. With enough pitches thrown, it is much easier to split out four- and two-seam fastballs.
Since I need at least two or three appearances in the same series or home stand to get my bearings on a reliever, and that’s not always available (rookies, for example), I find it difficult to automate the process, or even do it well manually.
For relievers, tricks like “find the fastest pitch and work down” won’t work when the guy only threw two sliders and a change-up before giving up that home run and getting the hook. If I can safely slam together a few outings, I can get better classifications faster. Since I can better see and understand the changes within a given park over time, I feel good starting there.
See what?
With a couple queries and clicks, I can create a chart that will help me find major shifts in system calibration that impact classification. I look in the derived data, not the initial nine values, since those are the easiest to comprehend.
Here’s a favorite, pfx_x in Philadelphia. Lateral spin movement (in inches) caused by the Magnus force generated by the rotation of our favorite raised-seam bearing sphere. Each point is the average pfx_x for one pitcher in one game.
click to enlarge

Same thing, but for Yankee Stadium. Both of them.

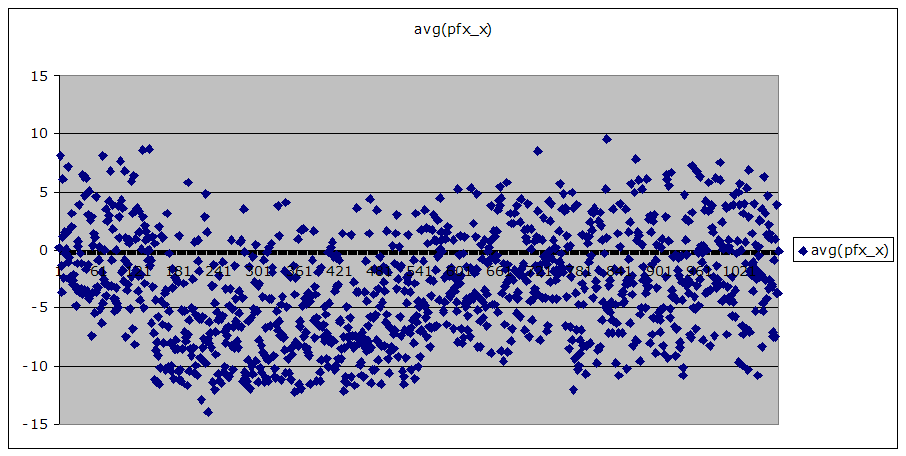
Here are the values I look at to see if something has changed at a park.
- pfx_x
- pfx_z
- pitch speed
- release points
In the References and Resources, you’ll find a link to some raw data and sample charts.
More decisions
Once each relevant shift has been found, what to do? What moves where? What’s the “right” value. Remember, a correction is needed to one or more the initial nine values, usually more. This is where I want you, the reader, to jump in (heck, anywhere along the way would be great). To whet your appetite, here are corrections to Philadelphia (which you won’t really be able to use, maybe).
After finding the shift points, as illustrated above, I found the corresponding corrections needed to the initial nine inputs. No, I did not back-in the changes from the derived data, I used the derived data to tell me where to look for major changes. The values I chose for the adjustments are non-scientific and non-precise. I’m not pretending to have precise data and methods.
I don’t suggest running these queries yourself. First, the game_id may not match yours. Second, you may not have such a database to begin with. In that event, you would want to make corrections, for example, to the data you downloaded following the instructions you can find at Brooks Baseball. You can use the files linked in the References and Resources to come up with your own corrections to the derived data.
update pitches p, atbats a, games g
set p.ax = p.ax + 7
where a.ab_id = p.ab_id and g.game_id = a.game_id and
g.home = 'phi' and g.game_id >= 2441 and g.game_id <= 3666
;
update pitches p, atbats a, games g
set p.ay = p.ay + 5
g.home = 'phi' and g.game_id >= 1976 and g.game_id <= 3867
;
update pitches p, atbats a, games g
set p.vx0 = p.vx0 - 2
g.home = 'phi' and g.game_id >= 2851 and g.game_id <= 3666
;
update pitches p, atbats a, games g
set p.vy0 = p.vy0 - 5
g.home = 'phi' and g.game_id >= 2874 and g.game_id <= 3867
;
update pitches p, atbats a, games g
set p.x0 = p.x0 - 1.5
g.home = 'phi' and g.game_id >= 2851 and g.game_id <= 3666
;
Notice the changes are staggered, not all falling on the same game ranges. I’ll use the depth and complexity of this as my excuse for not having a complete set of adjustments for you. Read below on helping out with the next steps.
References & Resources
Alan Nathan’s site contains the stuff you need to re-calculate the derived data. Brooks Baseball can show you how to get the data. You can download my zip archive of Excel files covering all 30 parks, including the max, min and average values for release points, speed and movement. Thirty sample png charts (two shown above) are also included. If you are eager to really work the problem, contact me and I”ll get you even more raw data.
Peter – We’ll get into some of this stuff for sure this weekend. For my version 2 rv100 stat, I’ll discuss some other stringer-related variances, too. For my version 3 rv100 stat, I’m looking for park effects in batted ball data. Or, I will look if I have time – have you found anything?
And, yes, Excel lets me format like mad, those were quickly generated and I didn’t bother formatting.
without the list you ask from Sportsvision, you’re wasting your time trying to normalize against a moving target. It’s like trying to create a climate norm for a part using just gametime temps and conditions. Everyone knows that the wind in Wrigley changes in to out, or that a rainstorm blows through, or that shadows creep across a field—all of which create changes that render attempts to create a single “weather park factor” relatively useless.
anonymous, I think that’s a good way to put it.
BTW, thanks to wunderground, you can often get near real-time weather data.
This definitely should be a discussion topic for the Summit. I think that it would help if Sportvision would make publicly available a list of major corrections that they have made at individual parks, the dates, and what correction factors should be applied to the data. Then we can do the work ourselves, with a single set of mathematically calculated correction factors instead of each of us individually estimating when and how to apply corrections.
If you are using Excel for your charts you can use format axis label so that it is below the chart instead of next to the x axis in the midst of all the data.