tDIBS: A Look at Defense Independent Batting Statistics Using Publicly Available Data

Jackie Bradley Jr.’s success this year isn’t a big surprise to tDIBS. (via Dennis Heller)
Editor’s Note: This piece was initially given as a presentation at the marvelous 2015 Saber Seminar.
Inspiration
The Error. The Unearned Run. Fielding Independent Pitching. xFIP. These increasingly complex concepts are fundamentally about sifting through all of the noise that is present in pitching statistics and determining how a pitcher should have done by acknowledging the factors outside of his control. The notion of ascribing value to players who perform well independent of their teammates and surroundings is what sabermetrics is all about; there is a great deal of value in finding out whether good or bad luck played a role in a player or team’s season. Fortunately for baseball analysts, the sport has an incredibly large sample size to work with; in no other sport is the team with the best record more likely to have earned it rather than lucked into it.
However, sometimes the sample size of 162 games, 600 plate appearances, or 200 innings pitched is not enough for our most commonly used metrics to give an entirely accurate representation of player value. The old adage – that for every bloop that manages to fall in for a hit there is also a line drive hit right at somebody – is not always true for every batter in every season. When the batting average on balls in play against Pedro Martinez rose dramatically for a single year in 2000, it is commonly accepted that he was simply unlucky. By using FIP, it can be seen that nothing significant or predictive about him as a pitcher changed or deteriorated in that one year.
To this end, we see DIBS (Defense Independent Batting Statistics) as an equivalent metric for batters. Using batted-ball profiles in conjunction with results-based statistics may make it possible to detect when a player may have been unlucky, even when their results-based statistics may paint a bleaker picture.
DIBS is a concept we were introduced to by Ben Jedlovec’s presentation on behalf of Baseball Information Solutions in Phoenix this March at the SABR Analytics conference. While BIS has access to proprietary data that helps fuel its calculations for its DIBS, our goal matches BIS’ – create a measurement of batting ability and offensive value separate from outcomes and past results. Ideally, this statistic will hold predictive value; much like FIP can tell us which players may have gotten lucky on batted balls in a certain year, DIBS uses batted-ball profile to predict outcomes independent of defense, park and result. tDIBS (the “t” standing for Tufts University, where we all are currently students) is an attempt to satisfy this goal using only publicly available data.
2014 Model
When originally designing the model earlier this year, we found that Gameday data was the best publicly available source for evaluating 2014 batted balls. Statcast data was not publicly available for the 2014 season except for a select few highlights.
The Gameday data we used included the following variables, as entered manually by a stringer in the press box:
- Batted-ball type (Fly Ball, Ground Ball, Line Drive, Pop-Up, and Bunt)
- Quality of contact (sharp, soft, neither)
- Location fielded – given by (x,y) pixel coordinates from a digital mockup of the relevant park
While these data were imperfect (take, for example, this Hardball Times piece by Colin Wyers on the effect of the press box location on batted ball classifications), it still provided valuable information about a player’s process, as opposed to just his results.
To turn these data into a model to predict batted-ball outcomes, we first needed to convert the pixel coordinates into feet, as the ratio will vary by park. To do this, we looked at plots of all batted-ball locations by park, finding the distance in pixels between home plate and a clearly demarcated wall, and compared that to the actual distance in feet. With these unique multipliers by park, we could then approximate the distance for each batted-ball in 2014.
Using these data directly to predict batted-ball outcomes still leaves us with a large problem: the distances calculated are where the ball was fielded, not where it landed. For ground balls, and to some extent line drives, this leaves the distance as very defense-dependent. A ground ball that gets through the infield will have a large distance compared to one that was fielded for an out. To reduce this problem, we used the publicly available April 2009 HITf/x data set to run a regression predicting batted-ball velocity and vertical launch angle from the Gameday variables (distance and quality of contact, run separately by batted-ball type). With this regression, a ground ball that makes it through the infield will have a slightly more favorable predicted velocity and angle than one that didn’t, but the difference will be much smaller than for, say, fly balls.
Finally, using our predicted velocity and vertical angle for each batted ball in 2014, we ran a multinomial logistic regression to predict probabilities of the five basic outcomes (single, double, triple, home run, or out). For fly balls, we used a simulation from a normal distribution to account for the uncertainty inherent in our imprecise data; this eliminated an issue where our model would predict too few home runs. By summing the probabilities of each type of outcome by player, we were able to come up with an expected DIBS batting line for each player.
With our model finalized, we were finally ready to see who got lucky, who got unlucky, and who performed exactly as they should have last year.
2014 Results
It may be interesting to see which kinds of players our model favors, what biases it may have, and a few examples of its intuitive (and counter-intuitive) findings. What follows are our top 10 largest underperformers and overperformers, using the difference between what our model projected their wOBA to be (“tDIBS wOBA” )and what their true wOBA was (“actual wOBA”), and measured using absolute difference in expected and actual wOBAs:

| Underperformer | wOBA | tDIBS wOBA | Diff | Overperformer | wOBA | tDIBS wOBA | Diff |
| Justin Smoak | 0.238 | 0.309 | -0.071 | Danny Santana | 0.365 | 0.272 | 0.093 |
| A.J. Ellis | 0.271 | 0.339 | -0.068 | Scott Van Slyke | 0.404 | 0.318 | 0.086 |
| Jose Molina | 0.202 | 0.263 | -0.061 | Justin Turner | 0.409 | 0.331 | 0.078 |
| Ryan Hanigan | 0.263 | 0.320 | -0.057 | Jose Abreu | 0.404 | 0.332 | 0.072 |
| Brandon Hicks | 0.244 | 0.299 | -0.055 | Giancarlo Stanton | 0.420 | 0.350 | 0.070 |
| Tommy La Stella | 0.290 | 0.346 | -0.056 | George Springer | 0.385 | 0.316 | 0.069 |
| Jackie Bradley Jr. | 0.234 | 0.284 | -0.050 | Kennys Vargas | 0.351 | 0.284 | 0.067 |
| Alberto Callaspo | 0.263 | 0.312 | -0.049 | Drew Stubbs | 0.365 | 0.297 | 0.068 |
| Aaron Hill | 0.276 | 0.324 | -0.048 | Mike Trout | 0.402 | 0.336 | 0.066 |
| Brayan Pena | 0.281 | 0.327 | -0.046 | Steve Pearce | 0.411 | 0.346 | 0.065 |
This snippet of our results shows us a variety of strengths and weaknesses in our model.
Seeing Danny Santana atop the list of 2014 overperformers was an immediate sign that our model may be measuring something real; here is a player with an tDIBS wOBA almost 100 points lower than how he actually performed last year, but the eye test and common sense matched much more closely with his tDIBS expected output than his actual results. He is not a good hitter, and shows no qualities — such as extreme plate discipline — that would mitigate his lack of batting skill (4.4 percent walk rate and a 22.8 percent strikeout rate). At the time of writing, Danny Santana’s 2015 wOBA is the worst in baseball (minimum 250 PA), an immense drop-off foretold by our 2014 model. In this case, our model was able to predict the unsustainability of Santana’s batting statistics due to his unimpressive batted-ball profile.
However, a seemingly troublesome trend also appeared on the overachievers’ side of the chart. Players such as Mike Trout, Giancarlo Stanton and Jose Abreu are clearly great hitters; why does our model suggest otherwise? In fact, it doesn’t blaspheme against these behemoths of baseball. Our model doesn’t suggest that these players are bad; their tDIBS wOBAs are very good, high above the league average. We posit that our Gameday 2014 model (due to the inherent limits of the “hardness” classifications that are present in the Gameday Sharp/Normal/Soft trifecta) simply couldn’t account for the fact that these three players hit the ball really, really hard on a consistent basis, and thus predicts a strong regression toward the mean as a result.
Overall, the correlation between tDIBS (expected) wOBA and wOBA for the 2014 season is 0.838. Several conclusions can be drawn from this value. First, this correlation is strong enough to suggest that the error in our model is not incredibly high; this is encouraging because generally what should have happened is not going to be entirely separate from what did happen – there should clearly be a high correlation between the two results. Secondly, this correlation is still low enough to show that our model is measuring something significantly different than simply results-based outcomes. Once again, this is necessary, because if the correlation were too high, there would be little to no value in all the effort that goes into calculating tDIBS wOBAs if they were nearly identical to actual wOBA for all players.
2015 (Statcast) Model
Fortunately, better batted-ball data for the 2015 season is now publicly available in a much higher volume than ever before. This “better” data has come in the form of Statcast. Statcast data allows us to use actual batted-ball velocities and distances to calculate probabilities, instead of estimations. Using Daren Willman’s Baseball Savant site as our data source, we were able to create a database of all batted-ball velocities for batted balls that have Statcast data available. Now, we were able to greatly simplify our model; we could now use one equation since the estimation regression was unnecessary. Using one multinomial logistic regression, we could predict the probabilities of each of the five basic outcomes (single, double, triple, home run, out). For fly balls, we were able to use the recorded distance as well; for all other hit types, we determined that the recorded distance (where the ball was fielded) was too defense-dependent, as explained earlier.
When Statcast data were not available for a batted ball, which is about 30 percent of all balls in play this season, we used the data from our old model to predict probabilities, finding the average batted-ball velocity for balls of the same type, with a similar distance. The 30 percent omission rate for Statcast data is not random – as Henry Druschel explored in this Beyond the Box Score article – which means that there could be a bias in the data we are using. But the bias is not so powerful that the model is not a significant improvement from using the Gameday stringer data for all batted balls. Using this streamlined model with improved data, and relying on our old model when Statcast information was not available, we were able to analyze the 2015 season to date and see which players have under or over performed their expected outputs thus far.
2015 Results
To see the power of tDIBS as a predictive tool, we decided to see how players who most underperformed and overperformed their respective expected wOBAs performed in a period of time following their under/over-performance. We chose the All-Star break as a natural cutoff point. These 20 players (10 Overperformers, 10 Underperformers), had the biggest difference between their tDIBS wOBA and actual wOBA in the first half this year.
| Underperformer | wOBA | tDIBS wOBA | Diff | Overperformer | wOBA | tDIBS wOBA | Diff |
| David Ortiz | 0.336 | 0.408 | -0.072 | Chris Young (H) | 0.329 | 0.256 | 0.073 |
| Robinson Cano | 0.295 | 0.353 | -0.058 | Dee Gordon | 0.322 | 0.250 | 0.072 |
| Chase Utley | 0.245 | 0.302 | -0.057 | Kris Bryant | 0.380 | 0.318 | 0.062 |
| Ryan Zimmerman | 0.251 | 0.306 | -0.055 | Bryce Harper | 0.481 | 0.420 | 0.061 |
| Wilson Ramos | 0.284 | 0.337 | -0.053 | Joey Butler | 0.353 | 0.292 | 0.061 |
| Logan Morrison | 0.282 | 0.335 | -0.053 | Billy Burns | 0.313 | 0.252 | 0.061 |
| Marcell Ozuna | 0.272 | 0.324 | -0.052 | Chris Colabello | 0.379 | 0.319 | 0.060 |
| Rene Rivera | 0.229 | 0.277 | -0.048 | Eddie Rosario | 0.322 | 0.268 | 0.054 |
| Jonathan Lucroy | 0.295 | 0.342 | -0.047 | Alejandro De Aza | 0.342 | 0.289 | 0.053 |
| Jordy Mercer | 0.260 | 0.305 | -0.045 | Randal Grichuk | 0.368 | 0.315 | 0.053 |
How about a graph? The following graph depicts the distribution of all players with more than 150 plate appearances when their wOBAs were graphed against the tDIBS wOBAs. In this model, speed was not factored into their tDIBS wOBA calculations. Each dot represents a player, with dot size dependent upon number of plate appearances and color intensity on speed score. Mouse over the dots to view the individual players stats.
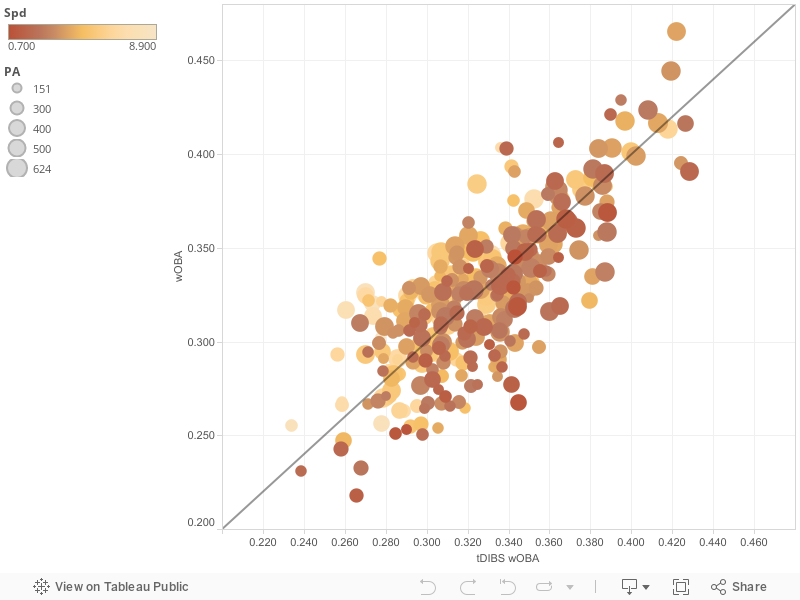
Let’s dive into these results, starting with Robinson Cano. Using only his batted-ball profile, we would have expected him to have a wOBA above .350, when his actual output was below .295. This is a massive difference, and led many people to declare Cano done, injured, or otherwise ineffective. Meanwhile, our model suggested that he had extremely poor luck on batted balls, and that he was not hitting the ball altogether differently from last season, when he ran a .335 BABIP and put up a .361 wOBA. In the 2nd half, Cano’s numbers have rebounded and then some, as he has put up a wOBA close to .400 since the break, validating tDIBS’s faith in his batted-ball profile and quelling talks of him being finished as a valuable player. Aggregated as a whole, these 20 players can show us something about tDIBS as well.
| Group | 1st Half wRC+ | 2nd Half wRC+ |
| Underperformers | 76 | 120 |
| Overperformers | 132 | 128 |
The fact that these two groups, so disparate in production in the first half, regress to almost exactly the same point thus far in the second half exemplifies the predictive power of tDIBS. Through Sept. 15, these are the 10 biggest positive and negative wOBAdiffs.
| Underperformer | wOBA | tDIBS wOBA | Diff | Overperformer | wOBA | tDIBS wOBA | Diff |
| Wilson Ramos | 0.267 | 0.345 | -0.078 | Chris Young | 0.344 | 0.277 | 0.067 |
| Victor Martinez | 0.277 | 0.341 | -0.064 | Chris Colabello | 0.403 | 0.339 | 0.064 |
| Hanley Ramirez | 0.322 | 0.380 | -0.058 | Kris Bryant | 0.384 | 0.325 | 0.059 |
| Jayson Werth | 0.297 | 0.355 | -0.058 | Billy Burns | 0.317 | 0.260 | 0.057 |
| Robinson Cano | 0.337 | 0.387 | -0.050 | Dee Gordon | 0.326 | 0.270 | 0.056 |
| Will Middlebrooks | 0.268 | 0.316 | -0.048 | Eddie Rosario | 0.324 | 0.270 | 0.054 |
| Rene Rivera | 0.218 | 0.266 | -0.048 | Randal Grichuk | 0.393 | 0.342 | 0.051 |
| Casey McGehee | 0.250 | 0.298 | -0.048 | Rusney Castillo | 0.322 | 0.271 | 0.051 |
| Jonathan Lucroy | 0.335 | 0.381 | -0.046 | Devon Travis | 0.391 | 0.343 | 0.048 |
| Dustin Ackley | 0.287 | 0.333 | -0.046 | Delino Deshields Jr. | 0.320 | 0.274 | 0.046 |
As you may notice, there is a clear speed effect influencing our results. It makes perfect sense that speed would correlate with outperforming this version of tDIBS wOBA, just as having elite speed helps run a high BABIP. To see this effect, we ran a regression and saw that the correlation of Speed Score to wOBAdiff, weighted by plate appearances, was .320. In other words, there was a demonstrable relationship between speed and overperforming tDIBS. To control for this effect, we added speed into our logistic regression at a batted-ball level. In this new model, the probability of each outcome can be affected by the Speed Score of the batter, and can vary by batted-ball type and by batted-ball velocity. Thus, speed can matter more for a weak ground ball than for a harder one. In this new model, the correlation between Speed Score and wOBAdiff was negligible. Faster players no longer overperformed to an outsized degree, and slow players had their expected lines adjusted towards a more accurate figure considering their footspeed. This version of the tDIBS model may be more accurate in predicting future results, by taking speed into account, but there is a tradeoff in complexity; no longer is the metric solely evaluating batted-ball profile as a means to derive a predicted batting line.
| Underperformer | wOBA | tDIBS wOBA | Diff | Overperformer | wOBA | tDIBS wOBA | Diff |
| Wilson Ramos | 0.267 | 0.329 | -0.062 | Chris Colabello | 0.403 | 0.330 | 0.073 |
| Hanley Ramirez | 0.322 | 0.381 | -0.059 | Chris Young | 0.344 | 0.279 | 0.065 |
| Billy Hamilton | 0.256 | 0.315 | -0.059 | Kris Bryant | 0.384 | 0.330 | 0.054 |
| Jayson Werth | 0.297 | 0.352 | -0.055 | Devon Travis | 0.391 | 0.340 | 0.051 |
| Victor Martinez | 0.277 | 0.331 | -0.054 | Jonathan Schoop | 0.364 | 0.315 | 0.049 |
| Sam Fuld | 0.263 | 0.313 | -0.050 | Addison Russell | 0.310 | 0.262 | 0.048 |
| Jose Ramirez | 0.266 | 0.312 | -0.046 | Randal Grichuk | 0.393 | 0.346 | 0.047 |
| Dustin Ackley | 0.287 | 0.331 | -0.044 | Rusney Castillo | 0.322 | 0.277 | 0.045 |
| Eric Sogard | 0.256 | 0.300 | -0.044 | Bryce Harper | 0.465 | 0.421 | 0.044 |
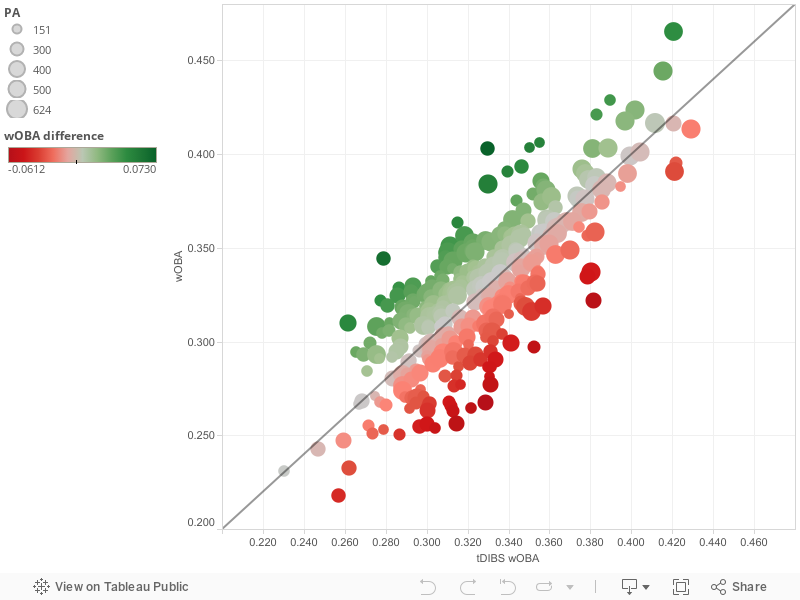
Let’s break out another graph. The graph below illustrates the distribution of players in our model with speed factored into the calculations of tDIBS wOBA. Similar to the last graph, dots represent one player with size corresponding to number of plate appearances. The more red the dot, the greater the positive wOBA difference. The more green the dot, the greater the negative wOBA difference.
Correlations
Now, it was time to see if tDIBS held up the test of predicting future results (in this case wOBA) better than wOBA itself. ERA estimators such as FIP, SIERA and kwERA have all been shown to predict future ERA at better rates than ERA itself; we hoped that tDIBS would do the same for wOBA. We split our data (through Sept. 13) roughly in half, creating a June 30 midpoint that would serve as the cutoff point for our split season analysis. We looked at the correlations, weighted by the harmonic mean of plate appearances in the two periods, using wOBA on contact, or wOBAcon. The correlations between the variables are shown in the following table:
| Statistics | Correlation |
| wOBACon/wOBACon | .392 |
| tDIBS wOBACon/wOBACon | .491 |
| tDIBS wOBACon/tDIBS wOBACon | .633 |
As you can see, tDIBS passes this preliminary test – it does predict future wOBAcon at a significantly more accurate clip than past wOBAcon does. This is important, as it shows that tDIBS has predictive value. Furthermore, the correlation of .633 between tDIBS from the first half of this analysis and tDIBS in the second half helps to prove that the metric is a consistent skill; there is a much higher degree of repeatability to this batted-ball based statistic than there is to the outcome based statistics like wOBA.
This makes sense on an elementary level, by taking an entire variable (in this case, defense) out of the equation, we get a more consistent measurement of some ability (in this case, batting skill). Generally, baseball skills that involve fewer total interactions are more consistent. For example, a pitcher throwing a pitch is one interaction. His fastball percentage (Fastballs Thrown/Pitches) will be a fairly consistent measurement, because it contains only this one interaction, and that interaction is largely his choice. His BABIP against will be a much more inconsistent measurement from start to start or season to season, because BABIP includes many more interactions, with the batter, with the defense, with the park factors, etc. tDIBS limits the number of interactions and as a result, produces a more consistent metric that holds significant predictive power.
Future Plans/Improvements
There is potential evolution in this research. Going forward, it would be possible to see how consistent results are for individual players, or distinct player types, over multiple year samples. If the same players are overperforming their expected outputs year after year, it may suggest that they have an attribute that predicts this discrepancy. The obvious analogue – the Tom Glavine and Jered Weaver pitcher-types who outperformed their FIP for years – show us that some players might have traits that may render Defense Independent statistics less useful. Furthermore, by analyzing players over multiple years we may be able to test the predictive capabilities that our model possesses over larger sample sizes.
Two other important influences on BABIP and hitting outcomes that are not incorporated into our model are park effects and shifting data. The former is incredibly hard to incorporate into any defense independent model because of the effects that stadium dimensions, atmospheric conditions, and other park factors have not only on outcomes, but on batted-ball data itself. Outfield dimensions are only one part of park factors. While aggregate run-scoring linear multipliers come with a relatively simple formula, assessing park factors in a DIBS model is considerably harder to isolate and adjust for. If part of the hitter-friendliness of Coors Field is that breaking balls don’t break as sharply, this will lead to them getting hit at a higher average velocity with greater frequency. Additionally, the expansive outfield at Coors gives each batted ball a greater chance of dropping for a hit once put into play. Finally, the thin air of Denver adds several feet to each batted ball, meaning that we would have to adjust a ball that was hit at the same velocity at sea-level. Because these effects are intertwined and inherently hard to divorce from each other in a workable model, park factors are much harder to incorporate in a DIBS model than in FIP (where they have basically no role), or OPS+ (where they are applied as a simple multiplier).
The other issue that arises whenever batted-ball profile is judged without defensive context is the growing prevalence of the shift. Our current model takes no defensive shifting into account; it assumes that all players will be defensed against the exact same way. This is not accurate in the present day. Underperforming, shifted against, players such as David Ortiz and Justin Smoak should not have the same expected probability of reaching base as player who uses all fields equally, like Joe Mauer or Xander Bogaerts, on a completely identical groundball toward the pull-side. As a result, players who see shifts often will likely continue to underperform their expected output, just as they often have low BABIPs due to the fact that they hit the majority of balls into a part of the field that is more densely populated with fielders.
tDIBS is an attempt to use the best publicly available data to analyze outcomes using batted-ball profile. The model isn’t close to perfect, but its significant predictive capabilities suggest that we may have sifted through the considerable noise and found at least some valuable signal.
References & Resources
- Special thanks to Andy Andres, Morris Greenberg and Ben Jedlovec for their assistance.
- Find the full tDIBS results here.
- Colin Wyers, The Hardball Times, “When is a fly ball a line drive?”
- Henry Druschel, Beyond The Box Score, “The early flaws of Statcast data”
Outstanding work, guys! Wow.
Very good stuff. I agree that park factors and shifting is a big problem, especially at the extremes (Coors Field, players who are shifted on a lot, etc.) .
One thing: Like DIPS and FIP, you are eliminating luck much more than defense. For example, for every medium hit ground ball that sneaks through the infield or pop fly that drops in the OF for a hit, much more is due to luck than the skill of the fielders. That is especially true since you don’t know or include the starting position of the fielders. (BTW, doesn’t STATCAST give you the position of the fielders, so that you can include that somehow in your model?)
I have always advocated LIPS rather than DIPS. In your case, I advocate tLIBS rather than tDIBS! 😉
Great job guys, as I’ve said exhaustively. Also as I’ve said exhaustively, multinomial logistic regression is good but likely not the best choice for this type of model, the reason being that while there is a clear hierarchy to type of outcome, the relationships between your explanatory variables that lead to those outcomes are not as straightforward as the model may assume. There are going to be a lot of outs that were really close to being doubles, or triples that were really misplayed singles. This will inflate your error a lot. HR and 2B are likely to be the most clear, but outs, singles and triples will give this model trouble.
Still, tDIBS is an amazing step in the public understanding, IMO.
Very interesting work, Ethan, Max, and Eric. I’m not fully familiar with all of the measures available in the Statcast data set, but I believe that vertical launch angle at the bat-ball contact point is included. This suggests that lateral launch angle might also be available. It seems like there may be some value to these two measures that simply using the distance traveled by the batted ball does not disclose. Have you considered launch angles or looked into including them in your model?
For this year, vertical launch angle is only released on homeruns, which limits its usefulness in this type of model. We hope it gets released for all batted-ball types next year. Lateral launch angle is not available at all yet in the data as far as I know, and would be harder to incorporate into the model, but would almost definitely improve accuracy if we used it right.
Very interesting work gentlemen. Thanks for sharing it and thanks for your contribution in sabr101x also.
did you guys happen to do a correlation between tDIBs and preseason projected wOBA or rest of season at the half? that may be an interesting comparison.
This is terrific! I’d really like to see a table of all the predictors and their odds ratios, if that’s possible.
I assume you’re looking for a table of the coefficients. It gets pretty messy because of all of the interactions, but here it is for the model that includes speed. The formula, in R notation, is outcome ~ batted_ball_type*(newVelo*Spd + newDist), where isFly is a dummy variable for fly balls, and newVelo and newDist are just batted-ball velocity, or distance from statcast, or estimated if Statcast is not available. Note that many are NA or not meaningful since all line drives have 0 for isFly, etc. Also, double is the left out group, so you would have to derive the coefficients by subtraction. Here you go:
y.level term estimate
1 Home Run (Intercept) 6.923847e-09
2 Home Run batted_ball_typeGB 4.868921e+05
3 Home Run batted_ball_typeLD 1.266245e+10
4 Home Run batted_ball_typePU 4.331472e-06
5 Home Run newVelo 8.918362e+07
6 Home Run Spd 8.142306e-02
7 Home Run newVelo:Spd 8.563670e-10
8 Home Run isFly:newDist 4.849532e-01
9 Home Run batted_ball_typeGB:newVelo 2.307737e+03
10 Home Run batted_ball_typeLD:newVelo 1.258850e-02
11 Home Run batted_ball_typePU:newVelo 2.776462e-06
12 Home Run batted_ball_typeGB:Spd 1.423366e+03
13 Home Run batted_ball_typeLD:Spd 4.269556e+07
14 Home Run batted_ball_typePU:Spd 4.331719e-02
15 Home Run batted_ball_typeGB:newVelo:Spd 3.825437e-08
16 Home Run batted_ball_typeLD:newVelo:Spd 2.579530e+06
17 Home Run batted_ball_typePU:newVelo:Spd 1.097198e+00
18 Home Run batted_ball_typeGB:isFly:newDist 9.686760e-01
19 Home Run batted_ball_typeLD:isFly:newDist 8.638800e-01
20 Home Run batted_ball_typePU:isFly:newDist 1.065652e+00
21 Out (Intercept) 3.683288e-01
22 Out batted_ball_typeGB 6.443152e-01
23 Out batted_ball_typeLD 1.528798e+00
24 Out batted_ball_typePU 2.327617e+00
25 Out newVelo 1.010427e+00
26 Out Spd 1.005103e+00
27 Out newVelo:Spd 9.925891e-01
28 Out isFly:newDist 9.958367e-01
29 Out batted_ball_typeGB:newVelo 1.027894e+00
30 Out batted_ball_typeLD:newVelo 9.781609e-01
31 Out batted_ball_typePU:newVelo 9.650124e-01
32 Out batted_ball_typeGB:Spd 1.007900e+00
33 Out batted_ball_typeLD:Spd 8.551151e-01
34 Out batted_ball_typePU:Spd 9.592472e-01
35 Out batted_ball_typeGB:newVelo:Spd 1.160742e+00
36 Out batted_ball_typeLD:newVelo:Spd 1.025806e+00
37 Out batted_ball_typePU:newVelo:Spd 1.007695e+00
38 Out batted_ball_typeGB:isFly:newDist 9.490066e-01
39 Out batted_ball_typeLD:isFly:newDist 1.045900e+00
40 Out batted_ball_typePU:isFly:newDist 9.460484e-01
41 Single (Intercept) 8.631747e-01
42 Single batted_ball_typeGB 9.807998e-01
43 Single batted_ball_typeLD 1.098840e+00
44 Single batted_ball_typePU 8.700298e-01
45 Single newVelo 1.894598e+00
46 Single Spd 1.301088e+00
47 Single newVelo:Spd 1.080819e+00
48 Single isFly:newDist 1.542001e+00
49 Single batted_ball_typeGB:newVelo 1.293298e+00
50 Single batted_ball_typeLD:newVelo 1.413753e+00
51 Single batted_ball_typePU:newVelo 5.040364e-01
52 Single batted_ball_typeGB:Spd 4.991988e-01
53 Single batted_ball_typeLD:Spd 2.169083e+00
54 Single batted_ball_typePU:Spd 1.286736e+00
55 Single batted_ball_typeGB:newVelo:Spd 8.487081e-01
56 Single batted_ball_typeLD:newVelo:Spd 1.995936e-01
57 Single batted_ball_typePU:newVelo:Spd 9.932355e-01
58 Single batted_ball_typeGB:isFly:newDist 9.958280e-01
59 Single batted_ball_typeLD:isFly:newDist 1.001601e+00
60 Single batted_ball_typePU:isFly:newDist 9.943471e-01
61 Triple (Intercept) 9.968045e-01
62 Triple batted_ball_typeGB 9.958489e-01
63 Triple batted_ball_typeLD 1.010035e+00
64 Triple batted_ball_typePU 1.007180e+00
65 Triple newVelo 9.936764e-01
66 Triple Spd 9.944812e-01
67 Triple newVelo:Spd 9.992647e-01
68 Triple isFly:newDist 1.011565e+00
69 Triple batted_ball_typeGB:newVelo 1.000000e+00
70 Triple batted_ball_typeLD:newVelo 1.000000e+00
71 Triple batted_ball_typePU:newVelo 1.000000e+00
72 Triple batted_ball_typeGB:Spd 1.000000e+00
73 Triple batted_ball_typeLD:Spd 1.000000e+00
74 Triple batted_ball_typePU:Spd 1.000000e+00
75 Triple batted_ball_typeGB:newVelo:Spd 1.000000e+00
76 Triple batted_ball_typeLD:newVelo:Spd 1.000000e+00
77 Triple batted_ball_typePU:newVelo:Spd 1.000000e+00
78 Triple batted_ball_typeGB:isFly:newDist 1.000000e+00
79 Triple batted_ball_typeLD:isFly:newDist 1.000000e+00
80 Triple batted_ball_typePU:isFly:newDist 1.000000e+00
Wow! That is something to take in. But yes, it’s what I was looking for. Thanks!