The Value of (In)Consistent Play in Major League Baseball

Howie Kendrick and the 2008 Angels had a very consistent offense (via Tracie Hall).
Introduction
In my last article on the topic of team consistency and whether that matters for overall performance, I summarized much of the work that has been done over the years. I won’t recreate that summary here—readers can follow the link to read the summary in its entirety. However, the short of it is that something approaching a consensus began to form, which held that, all else equal, it was better to have consistent run production and inconsistent run prevention. My initial findings ran somewhat counter to that, but that was using a metric to measure consistency I knew was likely a little rough.
This past March, I was lucky enough to be asked to present some research at the annual SABR Analytics Conference in Phoenix, Ariz. During my presentation of pitcher volatility (slides and video can be found here), current Boston Red Sox Baseball Operations Analyst Greg Rybarczyk (also known as the founder of Hit Tracker) asked me a very important question.
The gist of it was whether I knew for sure that higher or lower consistency was, in fact, better for teams, and whether that differed depending on whether a team had a great offense or a poor offense, or allowed tons or very few runs. I didn’t have an answer for Greg, so I set out to try to find one. To do this, I first wanted to try to find a (potential) better way of measuring team consistency.
A New Way to Measure Consistency
For this research, I’ve decided to leverage Gini coefficients to calculate a measure of consistency for both runs scored and runs allowed. For those that are not familiar with Gini coefficients, they are essentially a measure of inequality. Typically, they are used to measure the level of income or wealth inequality within a given area—often countries, but really you could look at any (political, geographic, etc.) category. The coefficients range from 1.0 to 0.0, with 0.0 representing a perfectly even distribution and 1.0 an imperfect distribution. I won’t get into all the technical nuts and bolts (this is a good place to start if you are curious), except to offer a quick example.
Say you have two countries: Skewedistan and Evensland. Both countries have 20 citizens and the same level of national wealth ($1,330,000), but the way that wealth is distributed across each of their 20 citizens is very different. Here’s what those distributions look like:
| Hypothetical Country Comparison |
|---|
| Skewedistan | Evensland |
| $1,000,000 | $66,500 |
| $90,000 | $66,500 |
| $75,000 | $66,500 |
| $52,000 | $66,500 |
| $20,000 | $66,500 |
| $10,000 | $66,500 |
| $10,000 | $66,500 |
| $10,000 | $66,500 |
| $10,000 | $66,500 |
| $10,000 | $66,500 |
| $10,000 | $66,500 |
| $10,000 | $66,500 |
| $10,000 | $66,500 |
| $10,000 | $66,500 |
| $1,000 | $66,500 |
| $1,000 | $66,500 |
| $650 | $66,500 |
| $350 | $66,500 |
| $- | $66,500 |
| $- | $66,500 |
Skewedistan has one citizen that holds $1,000,000 in wealth, leaving only $330,000 to be divided up amongst the remaining 19 citizens. In Evensland, each citizen has the exact same amount of wealth—$66,500. If we calculate Gini coefficients for each country, we end up with .8499 for Skewedistan and 0.0 for Evensland. This makes it abundantly clear how different the wealth is distributed in these two, equally wealthy countries.
It’s not difficult to make the leap to baseball. Imagine each game a team plays as a “citizen” and each run scored or allowed in each game as the “wealth” that is distributed across those games. Over the course of a season, teams will distribute some total amount of runs scored and allowed over individual games. Those distributions can look very different, even for teams with exactly the same total number of runs scored or allowed. Applying Gini coefficients to each team in a season provides us with a single, comparable metric that we can use as a proxy for how consistent each team is over the course of a season.
Now, Gini coefficients certainly are not perfect, but given their ease of calculation, I decided to try this method over others more focused on central dispersion (e.g. standard deviation, coefficient of variation, etc.), which have their own issues when dealing with baseball data.
Data
I leveraged data from a few sources to test the idea that consistency makes a meaningful difference in team performance.
First, I needed to calculate consistency scores for every team on a yearly basis for both their runs scored and allowed. To do this, I pulled game-by-game outcomes from Retrosheet for each team between 1971 and 2012. I then loaded the data into R and used the reldist package to calculate Gini coefficients for both runs scored and allowed by team, by year.
Second, I needed team performance data over the same time period. For this I relied on Sean Lahman’s invaluable database. From there, I pulled each team’s wins, losses, and a host of other performance data over the same time period (1971-2012). I calculated each team’s winning percentage, runs scored, and runs allowed per game.
Finally, and critical to this analysis, I need to calculate each team’s expected winning percentage and wins for each season. The standard way to do this is to use the Pythagorean Expectation. However, I also used Patriot’s methodology for determining the appropriate exponent for each team, each year. Okay, we have team performance data and we have consistency data. Time to start digging.
Analysis
Let’s take a look at our data. First, we can compare the trends and variability in runs scored and allowed per game over time:
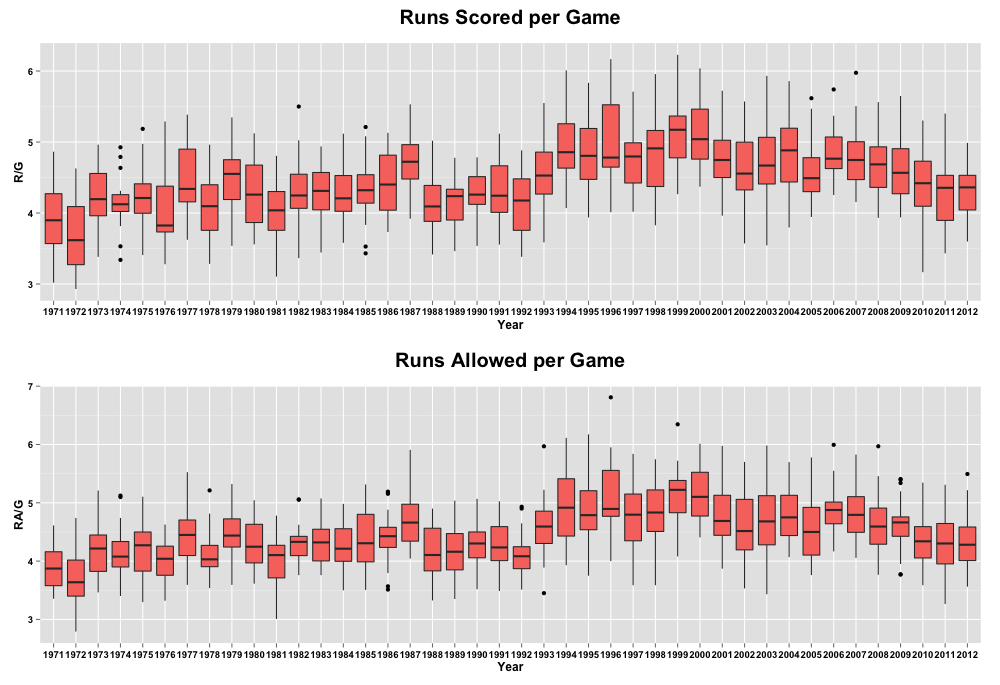
We can see the jump in average runs per game accelerating in the early 1990s and then the decline we are currently living through starting in about 2009. What does the trend look like for team consistency?
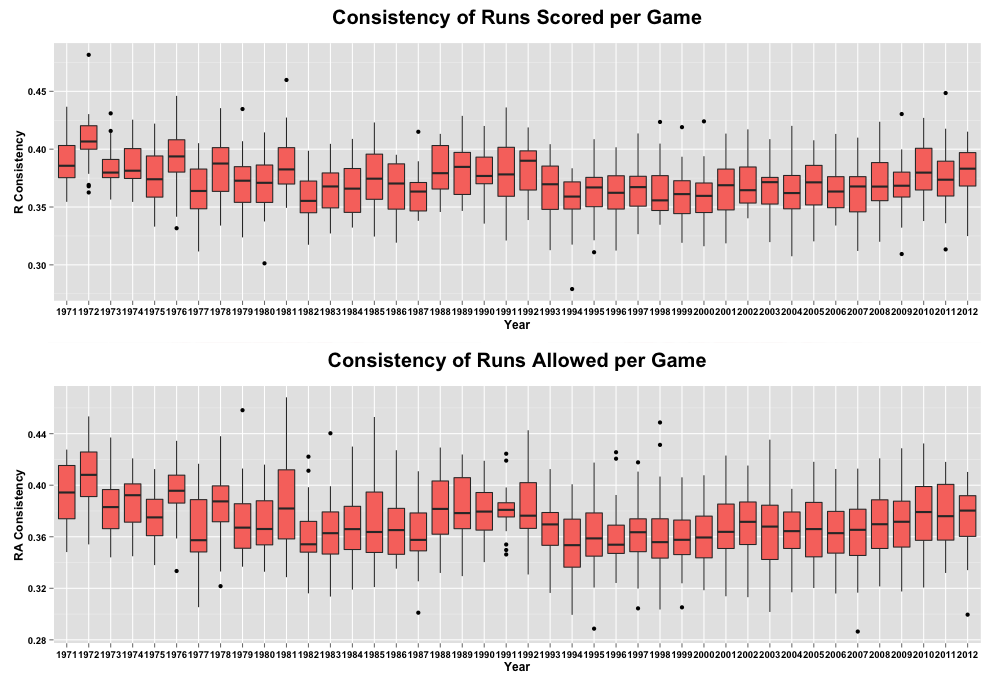
The first thing we notice is, while the consistency of scoring and allowing runs has also shifted since the early 1970s, it hasn’t moved in lockstep with the scoring environment, though there is definitely some relationship. Let’s plot each against the other to get a better sense of how they are related. Remember, a lower Gini coefficient means the runs are distributed more evenly, and that is our proxy for consistency:
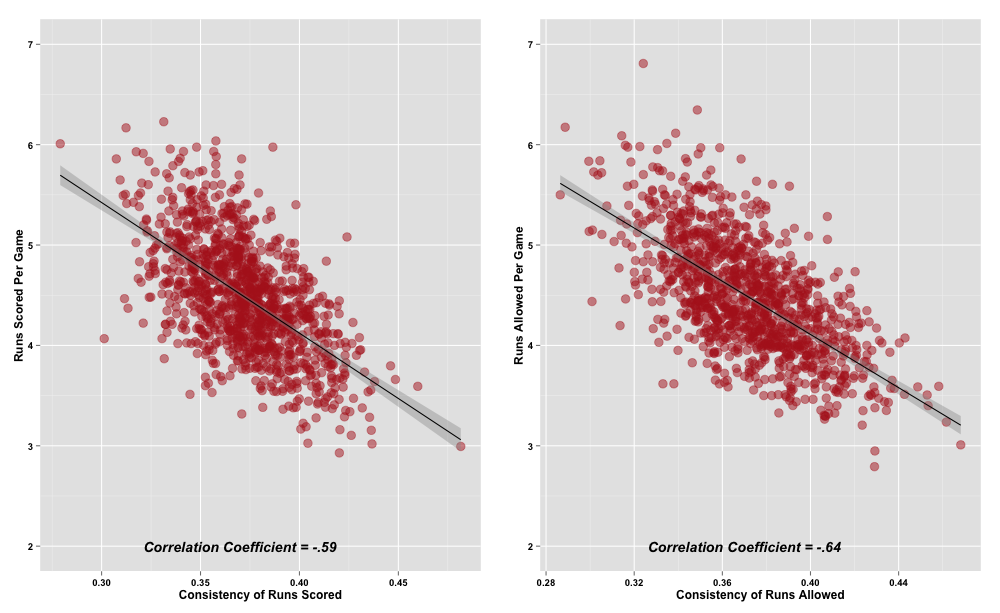
{kind=link}
Both the consistency of run scoring and run prevention have a negative, and decent sized, relationship with general run scoring and prevention ability. So, teams that score more runs per game also distribute their runs more evenly across their games. For better run prevention teams, it’s the opposite—fewer runs allowed per game generally leads to a less even distribution of runs allowed for a team over the course of the season.
What about the general relationship between consistency and winning percentage? The story here is a little different. If we just plot run scoring and prevention consistency against actual winning percentage we see two distinct patterns emerge: 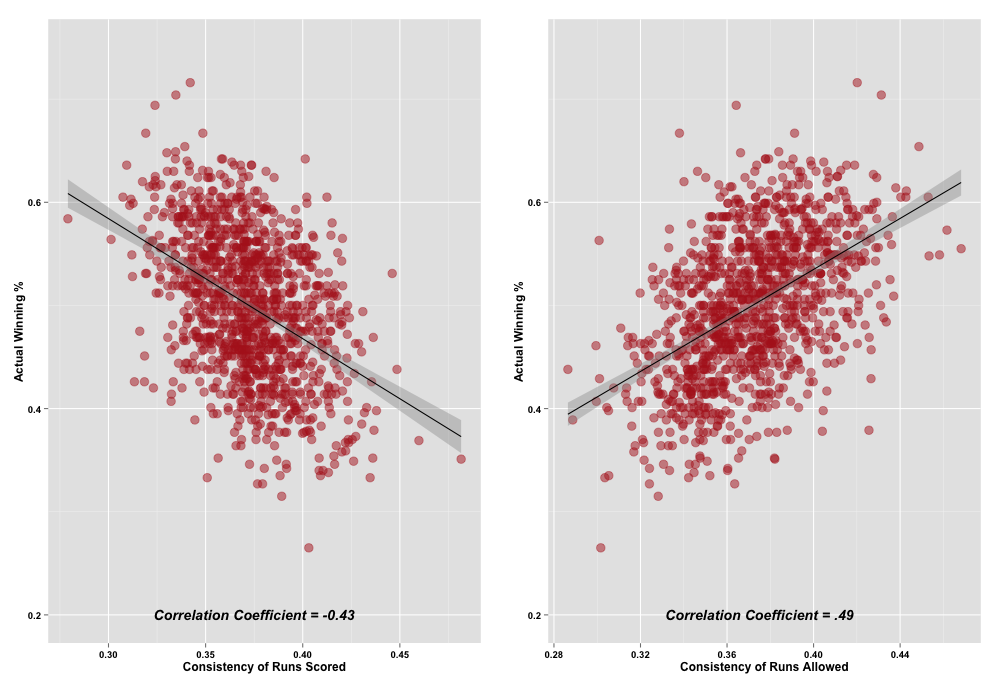
Less consistent offenses tend to win fewer games but the opposite appears true for run prevention. This generally aligns with previous results—both my own, and some of the earliest analysis that suggested teams would want their offenses to evenly distribute their runs, but want their defenses to perform in a more volatile fashion.
{kind=link}
Two important caveats here: 1) In neither case are the correlations controlling for the overall run scoring and prevention talents of a given team; and 2) each correlation is not controlling for the other type of run consistency.
So let’s model a teams actual winning percentage based on its runs scored and allowed per game, as well as its consistency:
| Consistency Model Using R/G, RA/G |
|---|
| Variables | Coefficient | Significance |
| GiniR | -0.345075 | *** |
| GiniRA | 0.415207 | *** |
| R/G | 0.090965 | *** |
| RA/G | -0.087405 | *** |
| Adjusted R^2 | 0.8931 | *** |
| Residual Standard Error | 0.02269 |
Interestingly enough, even after controlling for the run scoring and prevention abilities of the team, actual winning percentage is heavily influenced by consistency, and in the directions previously hypothesized. A word of caution: these results should not be interpreted as implying consistency is a better predictor than established winning percentage estimators like the Pythagorean Expectation. In fact, let’s model actual winning percentage as a function of the expected winning percentage predicted by the Pythagorean Expectation and see what, if any, difference consistency makes:
| Consistency Model Using Pythag |
|---|
| Variables | Coefficient | Significance |
| GiniR | -0.35854 | *** |
| GiniRA | 0.37825 | *** |
| PYTHAG | 0.87008 | *** |
| Adjusted R^2 | 0.8953 | *** |
| Residual Standard Error | 0.02246 |
Here we see that the Pythagorean Expectation is doing the majority of the work, but consistency does play a role and actually increases the accuracy slightly (R^2 higher and standard error lower). So, the bottom line is, if a team wants to win more games, it should shoot for an offense that scores a ton of runs and pitching and defense that give up as few as possible (no surprise there), and if it can optimize the consistency of both, that’s a nice added bonus.
What about over- or underperforming your expected wins? How does consistency play a role in a team essentially over- or under-achieving its expected performance? This was the original question that motivated my earlier article at FanGraphs, so here I want to take another stab at answering that question with our new measurements.
I modeled the number of wins above or below expectation for each team based on the consistency of its run scoring and prevention and also included controls for its overall run scoring and prevention (which gets to Greg’s great question/suggestion). Here are the results:
| Consistency Model Using R/G, RA/G, Adjusting for Wins Above/Below Expectation |
|---|
| Variables | Coefficient | Significance |
| GiniR | -52.4335 | *** |
| GiniRA | 63.1643 | *** |
| R/G | -1.8672 | *** |
| RA/G | 2.3104 | *** |
| Multiple R^2 | 0.1806 | *** |
| Adjusted R^2 | 0.1778 | *** |
| Residual Standard Error | 3.557 |
Consistency is essentially doing all the work in the model, with runs allowed pulling about nine percent more of the weight than runs scored.
Overall, the model explains about 18 percent of the variation in actual wins relative to expectation. The standard error is pretty large, however—about 3.6 wins in either direction—so it’s telling some of the story but is far from a precise predictor.
Now, this model is explaining what has happened, since I used the entire data set. What would happen if we apply the model to new data?
To validate this, I calculated the predictive R^2 of the model. The predictive R^2 tells you how much of the variation the model should explain when it is applied to data that was not part of the original data set. It is based on the PRESS statistic (Predicted Residual Sum of Squares), a type of cross-validation where the model is run multiple times, where one of the cases is left out each time to simulate training and test data sets.
The predictive R^2 for our model is 0.17, which is just a hair under the adjusted R^2 from the original model. That means we should expect the predictive power of the model to be much the same as it’s explanatory power when it comes to new data.
Now that we have a model of the impact of consistency on expected wins, I wanted to tease out this idea of how many more wins optimal consistency could mean to a team, depending on the talent of its offense and defense. To do this, I constructed a set of four average run scoring and run preventing teams based on data from 2010-2012. Each team had a different combination of consistency: 1) average for both runs scored and allowed consistency 2) bottom quartile run scoring consistency and average run prevention consistency 3) average run scoring consistency and top quartile run prevention consistency, and 4) bottom quartile run scoring consistency and top quartile run prevention consistency (the combination that the model tells us is optimal consistency).
Next, I took the model and applied it to each team to predict how many wins above or below expectation we should see. Here are the comparative results:
 Basically, the model suggests that a team will benefit from optimized consistency to the tune of roughly two wins compared to if they had average consistency–and this is controlling for the team’s run scoring and prevention abilities. And if you compare to teams with the least optimal consistency on both dimensions, the potential advantage jumps closer to three wins over the course of a season. That’s essentially Curtis Granderson, and he costs about $15 million per year.
Basically, the model suggests that a team will benefit from optimized consistency to the tune of roughly two wins compared to if they had average consistency–and this is controlling for the team’s run scoring and prevention abilities. And if you compare to teams with the least optimal consistency on both dimensions, the potential advantage jumps closer to three wins over the course of a season. That’s essentially Curtis Granderson, and he costs about $15 million per year.
Wrapping Up
While the results don’t suggest I can declare victory and go home, I am honestly excited. There are all sorts of variables that determine the gap between expected and actual wins, not the least of which is randomness or luck. The fact that we might be able to explain even a little bit of that through something like consistency is very interesting to me. Also, these results support some of the earlier work that suggested consistent run scoring paired with inconsistent run prevention might be optimal for a team.
Now, there’s more work to be done. First, I’d love to see these results validated against some kind of simulation so that we can “see” how the distribution of runs from game to game gets impacted depending on how other teams are distributing their runs. Second, the results here are based on a new measure of consistency, which means my previous research on hitter and pitcher volatility likely needs to be updated using this new metric at the individual level.
From there, the big leap needs to come from determining whether teams have any real control over how consistent or inconsistent they will be through roster construction. How does individual consistency scale to team consistency, and is it in any way repeatable so that teams could theoretically build rosters based on a combination of projected overall performance and consistency?
Those are big questions, but I think the current results suggest they are worth pursuing.
References & Resources
- All of the data and code (R and SQL) used for the research and analysis for this article can be found on GitHub (Team Consistency Code & Data)
- Thanks of course to the invaluable Restrosheet and Lahman Database
- Peter Rosenmai’s Lorenz Curve Graphing Tool (good resource for quick Gini Index calculations)
- Tom Hopper, Can We Do Better Than R-squared?
- Bill Petti, The Hardball Times, What Kind of Hitters are Volatile?
- Bill Petti, FanGraphs, Does Consistent Play Help a Team Win?
- Bill Petti, SABR Analytics Conference Presentation on Pitcher Volatility, 2014
- Patriot, W% Estimators
Awesome stuff, Bill.
When it comes to roster construction, maybe it would help to create a “Propensity To Dominate” stat for starting pitchers, which would give the probability that they would hold the opposition to say 1 run below expected over the length of start, or alternatively the probability that they would leave the game with their team in the lead. This would skew in favor of pitchers who absorb most of their damage in just a handful of starts, rather than those who are consistently average. (Quality Start % is probably the best existing proxy for what I’m talking about).
Would this be a correct reason WHY we get these results: A team that allows a high amount of runs in a game can still win while a team that allows zero runs will always win. The opposite for hitting, if you score zero runs you will always lose while if you score say ten or more you will still lose some small percentage of the time. So having inconsistent runs allowed leverages this relationship between extreme values of run scoring and wining, while having consistent runs scored avoids this relationship.
That’s not exactly it. The marginal value of runs drops off once you get above 5 or so in a game. Think of it this way: if you score 0 runs, you win 0% of the time. If you score 5 runs, you may win 70% of the time. But if you score 10 runs, you aren’t going to win 140% of the time.
Did you check how predictive consistency was on consistency? Because without that, there’s not too much going on here (Dean Oliver had a chapter in Basketball on Paper that had the same problem through a different lens). When you have a fixed RS/RA amount, or pythag expectation, then of *course* the team that HAD a large variance in RS will tend to underperform because it leveraged its runs relatively poorly, and a team that HAD a large variance in RA will tend to overperform because its *opponents* leveraged their runs relatively poorly. If consistency is actually strongly predictive of consistency, given a particular RS, then you’re on to something.
I’ve always felt QS% was a useful stat, and this research validates that to some extent. If you have two pitchers with an ERA of 3.80 (or a similar FIP, whatevs) but one has a QS% of 60 percent and the other of 74%, I’ll take the higher QS guy by a fairly wide margin all other things being equal. Even if a guy has a 4.40 ERA, but went out 20 times giving up 3 runs or less over 6-7 innings – that is huge. At the end of the day you just got to win 60% of your games.
It would be interesting to see research on how teams/players fare versus the strength of opposing pitching, also. Is there an advantage that can be leveraged to knowing whether your offense tends to over/under perform versus above-average pitchers.
this reminds me of the work done here on pitchers:
http://www.fangraphs.com/blogs/finding-value-in-pitcher-inconsistency/
regarding roster construction:
i used the data in the link above to calculate the inconsistency-WAR for edinson volquez this year, and it came out to ~3 WAR. Volquez RA9-WAR is ~1 and and FIP-WAR is ~0. So, if indeed this inconsistency was a repeatable skill, then there are certainly pitchers who are more valuable than is shown in their RA9-WAR/FIP-WAR. This means that inconsistency is an identifiable and potentially exploitable attribute for roster constuction.
Bill, great topic, but I want to be sure I’m clear over the role of consistency with respect to RS and RA. First you say,
“Less consistent offenses tend to win fewer games but the opposite appears true for run prevention. This generally aligns with previous results—both my own, and some of the earliest analysis that suggested teams would want their offenses to evenly distribute their runs, but want their defenses to perform in a more volatile fashion.”
But this is followed by:
“if a team wants to win more games, it should shoot for an offense that scores a ton of runs and pitching and defense that give up as few as possible (no surprise there), and if it can optimize the consistency of both, that’s a nice added bonus.”
If less consistent defenses tend to win more games (first quote), then by optimizing consistency, you mean, making defenses less consistent, right? When I first read the second passage, I thought you meant by “optimize” “increase” or “maximize”, but I take it that what you really mean wrt defense is “decrease” or “minimize”, is that correct? Optimize in this context just means go as far as possible on the consistency/inconsistency spectrum in the direction that results in more RS and fewer RA. In the case of offense, that means go towards 0 or maximum consistency, while in the case of defense it means go towards 1.0 or maximum inconsistency.
Likewise, when you describe your fourth scenario as:
“4) bottom quartile run scoring consistency and top quartile run prevention consistency (the combination that the model tells us is optimal consistency).”
I think you mean by bottom quartile the quartile closest to zero, which is the greatest consistency, while top quartile is the closest to one, which is the most inconsistency.
Is this correct?
The big question, of course, is whether consistency/inconsistency is something that can be altered, particularly inconsistency, I should think.
Am I misunderstanding, or are these charts backwards: http://www.hardballtimes.com/wp-content/uploads/2014/08/Gini.ActualW.v2-650×445.png
They seem to show that as runs scored become more consistent, winning % goes down, and the opposite for runs allowed, whereas your text says the reverse.
More consistent=lower Gini coefficient