xStats and Fantasy Uses for Statcast

You can now accurately project players like Buster Posey with a smaller sample. (via Chase N. & Joon Lee)
Editor’s Note: This is the fourth post of “Fantasy Baseball Preview Week!” For more info, click here.
Statcast made its public debut in 2015, and in the short period since there have been a number of debates regarding its usefulness. Almost immediately you began to see people quoting exit velocity numbers. It made sense, since exit velocity was, at the time, the only new Statcast data we had available. Unfortunately, and this was especially true of the early part of the 2015 season, it was soon recognized that a large swath of the exit velocity data was mysteriously missing. Many believed that if 30-35 percent of the data is missing, it isn’t a worthwhile resource to invest time and energy researching.
I am not a member of that group. Statcast is one of the greatest baseball tools to reach the public eye. It offers insights previously reserved for scouts: direct measurements of actual player ability. It allows for analysis that isn’t necessarily results driven, and as a result it will become one of the most impactful technologies on the game for a very long time to come. However, it is still very new, and unpacking the data into useable bit sized chunks is easier said than done. I hope to share a bit of the insight and techniques I have picked up on during my time playing around with this data, as well as some of the ways you can see use this information to aide your fantasy baseball team. I don’t claim to be an expert by any stretch of the imagination, but I hope you find it interesting nonetheless.
xStats
The moment I learned about publicly available exit velocity data, I fired up a spreadsheet and got to work. I began to combine the data to create a version of BABIP, and the following day I had created a version of wOBA. As it turned out, this version of wOBA, which I call xOBA, was actually quite good, and followed very closely with the true game results.
At first, xOBA was calculated using exit velocity and batted ball type—ground ball, line drive, fly ball and pop up. Using these two variables I created a simple lookup table for single, double, triple and home run percentages. To find the value of a particular batted ball, you need only scroll down the table until you find the correct exit velocity, then go right until you find the correct batted-ball type (you can also view it here).

This method produced results that were okay but not especially great. They had R² values around 0.58, along with pretty high error rates, but these values had a few prescient observations. For example, in July of 2015 it claimed Daniel Murphy would have a dramatic uptick in power numbers, which certainly turned out to be quite true. These numbers also suggested Zack Greinke’s 2015 success was unsustainable and due for steep regression, which we unfortunately witnessed in 2016.
There were bad predictions as well. Eric Campbell was a darling of the system with his sustained high exit velocities and high line drive rates. That didn’t work out very well.
This was a very early version of the stats I now maintain on xStats.org. It had a lot of flaws, but it was a proof of concept. It showed that with simple data about batted-ball quality you can roughly estimate offensive performance. Remember, you only need exit velocity and batted-ball type to use that lookup table. Two variables, very simple, and yet it produced the results you would expect. Mike Trout, Bryce Harper and Miguel Cabrera were the top batters. Clayton Kershaw, Chris Sale and Max Scherzer were the top pitchers. The consensus top players bubbled to the top, while the weakest settled on the bottom.
Sure, there was room for nuance in the gray areas in between. These early versions were pretty ham-fisted due to a lack of consistent data. Remember, 30-35 percent of the exit velocities were missing, and vertical launch angles were not yet available. Even with these limitations, you could tell Statcast had the potential to highlight underlying skills. Balls in play aren’t random; that notion has been thoroughly debunked. Now we need ways to tap into this information.
In 2016, MLB began to publish much more Statcast data on Baseball Savant, filling in much of the missing data from 2015. We are still missing about 10 percent of the data, but that appears to be a limit to Statcast itself as opposed to any sort of deliberate withholding of information. We were also given vertical launch angles and hit distances for batted balls.
In light of the new data, I substantially upgraded this old lookup table system and moved to one that incorporated both horizontal and vertical launch angles. Horizontal angle, you ask? Well, since Statcast doesn’t provide this information, you can calculate it using the Gameday fielding location. You take the fielding location and the location of home plate, apply a little trigonometry, and you wind up with an angle. Let me walk you through my process. (Disclaimer — math ahead! If you don’t care about the math, feel free to skip ahead.)
How It Is Calculated
In May of last year, I described how I split batted balls into five-degree by five-degree launch windows. In other words, I split the field into five-degree arcs from foul pole to foul pole. There are 90 degrees in the play area, so 90/5 = 18, plus a few in foul territory to cover those balls as well. Vertically, you have balls hit straight down, -90 degrees, and balls hit straight upwards, +90 degrees. That is a 180 degree arc, divided by five = 36. So, that creates an array that is roughly 22 wide and 36 tall. We can call that approximately 800 possible launch windows.
Next, I split each window into 65 buckets based upon their exit velocity. Each bucket held two mph worth of balls. So, for example, a ball hit at 88 mph would enter one bucket, but a ball hit at 90 mph would enter a second bucket. The 89-mph ball in between would be shoved down into the 88-mph bucket. If you take those 800 windows and multiply by these 65 buckets, you wind up with about 51,000 combinations. In practice only about half of these were used, many of which only contained a small number of batted balls.
That was an older version of my system, which I originally described on RotoGraphs last May. Since then, this system has undergone a pretty significant upgrade, although it still follows many of the same principles I just outlined.

I still split balls into launch windows and split those launch windows into smaller buckets depending on their exit velocity, except now I do this many times, with different starting points and varying sized windows and buckets. Some of my launch windows are 15 degrees by 15 degrees, others are three by three. Some are six by six, and others are five by five. Some buckets hold 12 mph, others hold two mph, some hold seven and others hold five.
I find the average success rates in each of these cases and weight them based on the size of the bucket and their distance from whichever batted ball they are trying to categorize. This places a heavier weight on batted balls that are more similar and a lighter weight on those that are very dissimilar.
Having lots and lots of buckets of different sizes and locations allows me to approximate a probability distribution. The widest buckets represent the widest parts of the normal distribution, perhaps out by the third standard deviation. The smallest buckets represent values closer to the mean, closer to the first standard deviation. If I correctly weight and combine these values, I should be able to generate a good approximation for the probability of a hit.
Once I have performed all of these actions, I am left with a probability for a single, double, triple and home run for each batted ball. I want to stress that I am calculating 1B%, 2B%, 3B% and HR% on a case-by-case basis. There are other possible methods. I have seen some people figure out the probability of a hit versus an out first, then split the hit probability up later. I have seen others estimate the batting average and slugging percentage of each ball without concerning themselves with singles, doubles, etc. xStats focuses on finding singles, doubles, triples and home runs first, then translates these values to batting average, slugging and wOBA after the fact.
Running Speed
Running speed plays a large factor in success rates, so I need to account for it in some manner. I currently employ a method that measures foot speed in three different ways. First, I find the batter’s infield hit rate compared to league-average success rate for similarly hit balls. Next I find how often a batter extends a hit to two or more bases compared to the league-average rate based upon similarly hit balls.
For example, if a certain batted ball is almost always a double, but a batter consistently settles for a single, then he is treated as a slower runner, or vice versa. Finally, I find how often a batter extends a batted ball for three or more bases compared to the league average triples rate. Note, home runs that go over the wall never apply to any of this, but inside-the-park home runs do. Also note that I treat hits and bases reached on errors as equivalent actions in regards to calculating these speed scores.
This method leaves a lot to be desired, but it is all I have at the moment, and I haven’t been able to think of a better way to estimate running speed. Remember, the goal here is to estimate hit probability on a case-by-case basis, so any running speed metric probably should reflect that. Ideally, I could implement home-to-first times, home-to-second times, etc., but unfortunately I don’t have access to that information. So, for now, this is how I am estimating foot speed.
Park Factors
The raw data supplied by Statcast via Baseball Savant has some ballpark bias. Each ballpark has radar stations set up in slightly different locations, perhaps with a slightly different calibration, and as a result they offer different readings for similarly hit balls. To correct for this, I am employing a method described on Baseball Prospectus, which aims to offer slight corrections to exit velocity based upon both ballpark and game time temperature.
In addition to this exit velocity correction, I use the FanGraphs Park Factors to offer slight adjustments to hit probabilities. Eventually I hope to swap this out for a method that takes horizontal launch angle into account.
Does It Work?
This is all well and good, but I suppose we should check to see if this system is descriptive of the environment. In the table below, I have included stats from three players, decided by a random number generator, plus Mike Trout—I couldn’t show stats without including him. I’ve included both xStats and actual recorded stats side by side.
| DJ LeMahieu | Jarrod Saltalamacchia | Chris Davis | Mike Trout | |||||
|---|---|---|---|---|---|---|---|---|
| xStats | Actual | xStats | Actual | xStats | Actual | xStats | Actual | |
| AVG | .347 | .348 | .176 | .174 | .225 | .222 | .308 | .315 |
| OBP | .414 | .416 | .291 | .288 | .334 | .331 | .428 | .433 |
| SLG | .510 | .495 | .366 | .351 | .482 | .463 | .572 | .550 |
| BABIP | .382 | .388 | .232 | .226 | .282 | .282 | .351 | .371 |
| wOBA | .386 | .391 | .288 | .281 | .346 | .340 | .423 | .414 |
For the most part, there is a lot of strong agreement. The batting averages are all within a few points of each other, as are the on-base percentages and weighted on-base averages. Slugging and BABIP have some disagreement. In general, xStats feels all of these guys should have higher slugging percentages, and perhaps Trout got a little lucky with his BABIP. Overall, though, the stats appear to line up nicely. The better players have better stats, and they are roughly on par with what you would expect. This passes the eye test.
These are just four players, though. I’ve calculated the correlations for these stats for all batters who had at least 100 plate appearances in 2016. The correlations are pretty strong, ranging from 0.713 for BABIP up through 0.865 for slugging. So it appears these stats are at least descriptive of events that happen on the field. There are many theories regarding best practices for implementing this information. Some see xStats as a measurement of luck, others as a measurement of skill, and some perhaps even view it as a predictive tool.
| xAVG | xOBP | xSLG | xBABIP | xOBA | |
|---|---|---|---|---|---|
| R | .799 | .863 | .865 | .713 | .855 |
| R² | .638 | .745 | .748 | .508 | .731 |
But Is It Predictive?
I took the 2015 xStats, the 2016 Steamer Projections, and the final 2016 stats for every batter who had at least 100 plate appearances in both of 2015 and 2016. I scaled xStats to match Steamer’s projected plate appearances, then calculated the mean squared error for both systems.
| 1B | 2B | 3B | HR | |
|---|---|---|---|---|
| xStats | 581.8 | 60.2 | 3.2 | 58.0 |
| Steamer | 579.5 | 61.7 | 3.7 | 51.4 |
Neither Steamer nor xStats came out as a clear winner in terms of hit projections. xStats is superior at projecting doubles and triples, while Steamer is superior with singles and home runs. Steamer’s advantage with regard to singles is only slight, and it appears to correlate with age to a certain extent. In fact, all of these values seem to correlate with age.
With younger players—those under 25—xStats is significantly better at predicting singles and triples while also significantly worse at predicting home runs. In older players—those over 30—xStats is significantly worse at predicting triples, but it is better with doubles, and the disadvantage with home runs is greatly reduced.
| Age | 1b | 2b | 3b | hr | Number |
|---|---|---|---|---|---|
| ≤25 | 1.734 | 0.107 | 2.072 | -2.350 | 68 |
| ≤30 | -0.057 | 0.103 | 3.292 | -2.162 | 226 |
| ≥30 | -0.191 | 0.952 | -2.148 | -0.400 | 122 |
Considering all of this, you may assume xStats should be pretty good at estimating BABIP and batting average, but not necessarily slugging percentage. That is what I assumed, anyhow. Unfortunately, it turns out to be false. In reality, xStats is significantly weaker at predicting AVG, OBP, SLG, BABIP and wOBA. The mean square error is larger, and so is the standard deviation.
| Age | AVG | OBP | SLG | BABIP | wOBA | Number |
|---|---|---|---|---|---|---|
| ≤ 25 | -.000390 | -.000742 | -.002062 | -.000669 | -.000900 | 68 |
| ≤ 30 | -.000331 | -.000484 | -.001916 | -.000423 | -.000684 | 226 |
| ≥ 30 | -.000309 | -.000664 | -.001491 | -.000363 | -.000670 | 122 |
There are many possible explanations for why this may be the case. With BABIP in particular you have a pretty simple equation:
(H – HR)/(AB – HR – K + SF)
I’m going to rearrange this equation so it fits our problem a little better. First, I define M to be equal to singles + doubles + triples. Next I will redefine the denominator: PA – BB – HBP – K. We are ignoring obstruction and interference calls, since they are so uncommon.
The new equation, which should be equivalent to the original:
M / (PA – BB – HBP – K)
Judging by the mean squared errors, xStats should be at least on par with Steamer at predicting M. It is strictly better at two of the three components and only slightly worse at the third. We define the plate appearances to be equal in both cases. That leaves us with three variables to explain the dramatic difference between xStats and Steamer: walks, hit by pitch and strikeouts. As you may have noticed from the way I described xStats earlier, none of these three variables are covered by the system in any regard, but rather their rates are assumed to remain constant over time.
This isn’t a terrible assumption, since both strikeout and walk rates tend to remain pretty consistent, but assuming this sort of linear projection clearly is problematic. With larger sample sizes this problem lessens, and I have found that using one and a half seasons of xStats data is more predictive than merely using a single season. This pushes me to believe two full seasons of data should be better still, although time will tell.
It Isn’t All Bad News!
Up to this point I have mentioned the weaknesses and shortcomings of xStats, but there are many advantages as well. For one, this system is pretty good at evaluating players with even relatively small sample sizes.
Earlier I showed the predictive power for batters who had only 100 plate appearances in the xStats system, which represents, perhaps, 60 to 70 balls in play once you throw out the strikeouts and walks. Keep in mind, I’m not using minor league stats, career numbers, aging curves or anything along those lines. Using only this small number of batted balls, assuming strikeout and walk rates remain constant, even with all of these problems, xStats still outperforms Steamer in several categories. More importantly, many of xStats’ weaknesses can, and will, be improved.
| 1b | 2b | 3b | hr | Number |
|---|---|---|---|---|
| 0.253 | 1.188 | 1.583 | -1.739 | 99 |
All Information Is Good
More information is good, that is my mantra. Okay, so one year’s worth of xStats data isn’t as predictive as one of the best projection systems publicly available. It would be pretty crazy if it were. It is close, though, and it offers a different perspective on the game. It appears, based on the relatively small amount of data we have, that exit velocity and launch angle stabilize pretty quickly.
It didn’t take long for people to recognize that exit velocity isn’t quite enough information to judge a player. You can have a 105-mph batted ball that’s a one-hop ground ball to the shortstop or a home run. A 90-mph ball could be an easy ground out, an easily fly out, or a double down the line. Generally speaking, higher velocity is better, but it isn’t enough on its own.

Batting average and slugging percentage both increase with exit velocity. Beyond 110 mph the data are a bit iffy, since we start to run into sample size problems and perhaps measurement error, but between 60 and 110 mph you can see a clean and obvious trend. Balls hit at 80 mph have a batting average around .100, and those hit at 100 mph have a batting average closer to .520. So more is better, generally speaking.
This isn’t enough to perform an analysis of players, though. As part of xStats, I have developed a stat I like to call Value Hits, which represent the highest value hits in the game. They are determined by multiplying a batted ball’s probability for success—single, double, triple or home run—and multiplying it by the appropriate linear weight. If this total value is equal to or greater than the linear weight for a single, it registers as a Value Hit.
About seven percent of batted balls meet this cutoff criterion, but those that do have an .879 batting average and 2.606 slugging percentage. Eighty-one percent of Value Hits are extra-base hits, and 85 percent of home runs are Value Hits. In some ways, Value Hits are quite similar to Barreled Balls, but their method of calculation is quite different.

The distribution of Value Hits varies quite a bit with horizontal launch angle. Down the lines there are large concentrations, since many balls hit in those locations are doubles. In the left- and right-field gaps you see clusters of relatively short Value Hits, with some traveling barely 250 feet. Deeper in the outfield, out beyond 350 feet, there is a large home run belt. In left field, the home run belt is shifted a bit towards center field, while in right field it is more down the line. That’s a bit interesting, although it shouldn’t be surprising to anyone.
Around the chart, you’ll see apparently random blips of Value Hits here and there, some way off in foul territory. Those are the result of various Statcast measurement errors.
I hope, in looking at this chart, you can see how important it is to include all of the data available in your analysis of Statcast data. Exit velocity is great. Vertical launch angle is great. Horizontal angle is necessary, too. If you subtract one of these variables, you immediately begin to run the risk of coming to the wrong conclusion.
If I tell you a ball is hit at 92 miles per hour on a 10-degree vertical angle, you may assume it is an out, or perhaps a single. If I then tell you the ball was hit on a 43-degree horizontal angle, you would know it is almost assuredly a double. That’s a big difference between a likely out and almost assuredly an extra-base hit.
Now that we’ve got a good handle on xStats and the limitations of both it and Statcast data, let’s explore some ways you can put Statcast and/or xStats data to use for your fantasy baseball team this season.
Best Suited for Small Sample Sizes?
Small sample sizes have long been the enemy of the baseball analyst, but Statcast data may actually be best suited to fill this gap. Exit velocity and launch angle seem to be pretty consistent over time, and they seem to stabilize after a relatively small number of balls in play, perhaps 60 to 100 or so.
This means the data should be able to rapidly adapt to changing circumstances, whether a player has changed his approach, suffered an injury, or whatever it may be. Whether you are looking at xStats or the raw Statcast data on Baseball Savant, you may be best served to look at a relatively small sample size of data–the last 100 plate appearances, maybe the last 150. As I showed before, even small sample sizes of this data have predictive qualities.
Russell A. Carleton wrote an outstanding piece back in April of 2016 about the reliability of exit velocity over time. In it, he made the following comment, which is a sentiment I believe will come to embody the new Statcast era of baseball.
There’s a tendency to view baseball players as their season stats. If a hitter puts up a .300 average during a season, we tend to look back on that season and assume that he was .300 hitter all along, from April to September. What if he was really a .280 hitter in the first half, then at the All-Star break, he made an adjustment and was really a .320 hitter in the second half?”
Statcast data give us the ability to rapidly adapt to changes in player ability, whether it is from injury, slumps, or a tweak to his approach at the plate. Within just a few dozen batted balls, we can build a profile that is not only accurate, but predictive of future success.
You Can Project With Exit Velocity, Too
Say you have a player who has a sufficient number of batted balls—50-100 balls in play, which may be 70-150 plate appearances depending on the strikeout and walk rates. With this number of batted balls, assuming the player is healthy, you can generally assume the extreme high end of his batted balls represent his true talent maximum exit velocity. Using that as a benchmark, we can build backwards to determine how the rest of his batted balls may be distributed in the future. Let’s work through an example.
Exit Velocity Example
I went through my database of exit velocities and selected 100 random balls in play from an arbitrary batter. I’ll identify the batter at the end, but try to guess as we go along! I’ll give you two hints: He’s very popular, and he plays on the West Coast.
Okay, so here is a histogram mapping out his exit velocity distribution for these 100 balls in play.

From this we can tell a few things: First, he has some good power, although not a spectacular amount. You can tell because he’s hitting a good number of balls above 100 mph, but none higher than 110 mph, and not an especially large number above 105 mph. Perhaps 15-20 HR power potential? Somewhere in that range.
In terms of frequency, his peak is around 100 mph, and even from these random 100 BIP you can see a pattern of steadily ramping up to this velocity starting around 85 mph, but with some dips. This is important.
Most batters will tend toward a negatively skewed distribution of exit velocities. In other words, the higher exit velocities will be a bit more common than lower velocities. This isn’t true for all batters! You have to be careful and evaluate on a case-by-case basis.
In this data, he has 40 percent ground balls, 30 percent line drives and 25 percent fly balls, along with 9.6 percent walks and 9.6 percent strikeouts. In these 100 BIP he had a .330 batting average, .545 slugging percentage and four home runs. However, he historically has closer to 50 percent ground balls, 24 percent line drives and 21 percent fly balls. In the future, we might expect his rates to converge on those his career rates, so I’ll add in 24 more ground balls, two fly balls, and one pop up. Since we know balls are mostly missing between 75 and 100 mph, I selected 27 random batted balls hit between those velocities.

After adding in these batted balls, the area to the left of his peak frequency filled in quite a bit, so the graph appears to be smoothed out. Using these batted balls as an adjustment, his batting average and slugging drop to .294 and .462, respectively.
This is a sort of quick and dirty projection you can run using only exit velocity data and batted ball type frequency data, which you can pull from Baseball Savant. In this case, we took a sample that was heavily skewed toward the high end of the player’s apparent skill set, and we filled in some of the mid-range values to fit his frequency histogram to a probability curve we might expect from future performance. We did it using semi-random batted balls, constraining the exit velocity to the bounds we knew were missing from his sample. This is the sort of projection you can work out for a player in a spreadsheet in just a few minutes.
Let’s see how this all compares to his actual game stats, which happened to include 870 batted balls.

Can you guess the player? It is probably borderline impossible, but maybe you had fun trying. It is Buster Posey, and over this period of time he had a .305 batting average and .464 slugging percentage. Pretty close to that .294 and .464 we estimated after a minor adjustment to 100 batted balls. Note that the ground ball, line drive and fly ball definitions I used here might differ from other sources, but that shouldn’t change any of the arguments or methodology.
Exit Velocity Can Identify Injury
When players endure injuries, particularly to the legs and arms, their bat speed tends to drop, which you can measure and track through exit velocity. If a batter has a sudden drop in velocity, particularly their maximum velocity, you can often assume they are suffering from an injury.
This injury or may or may not be public information, but their quality of batted balls is a telltale sign. A dip in production can often lag behind a dip in exit velocities by a bit, which can help you identify players to seek out or avoid during the course of a season. Or, perhaps, target going into a season by projecting a return to health.
For example, Michael Conforto had his exit velocity suddenly drop last May prior to a demotion to Triple-A. Injury wasn’t initially a public concern, to my knowledge, although it made the news cycle several weeks later when he received a cortisone shot.
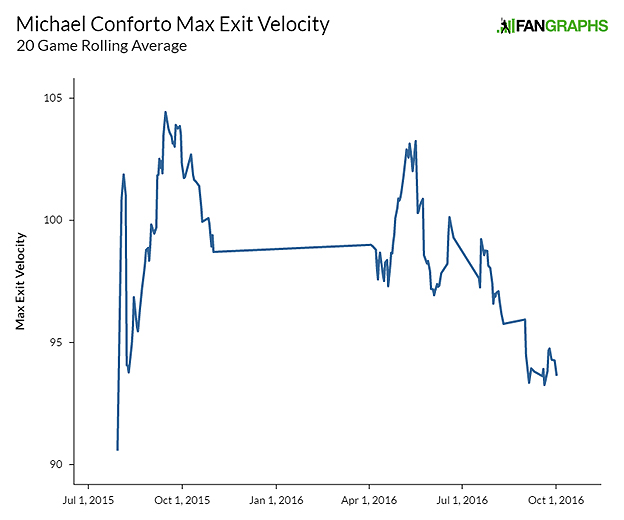
Conforto entered the league in mid-2015, and over the course of his first few weeks he hit the cover off the ball, but he had games where his maximum exit velocity were 48 mph and 66 mph. These two games brought down his early rolling average quite a bit, and explains that early lull in velocity.
From mid-September 2015 through the end of April 2016, a period that includes postseason success against several of the best pitchers in the game, Conforto maintained elite exit velocity, a tribute to his raw ability. His average velocities were similarly beautiful.
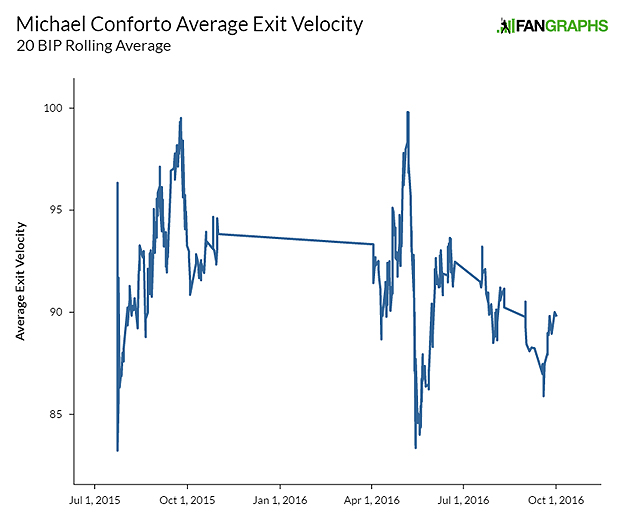
Then, in May, both his maximum and average velocities took a turn for the worse. Slumps happen, yes. Exit velocity will often go down in a slump for a large number of reasons. This chart depicts something beyond a slump, though. Conforto steadily shed maximum exit velocity over the course of weeks. This is the sort of pattern you should be looking for when analyzing players for injury concerns.
The Data Is Descriptive and Predictive
Statcast and xStats are descriptive and predictive in a way quite different from other stats. Pitcher FIP might be the most comparable in this regard. The goal is to attribute a larger portion of game results to skill while shrinking the portion attributed to luck. There are problems with xStats that I have outlined, mostly stemming from the difficulty of estimating foot speed and missing Statcast data, so luck hasn’t been completely isolated by these stats, but it is a lot closer than the alternatives.
You’re probably more accustomed to measuring luck with batting average on balls in play and left on base percentage, but these stats come with their own host of problems. Both pitchers and batters have varying degrees of control over launch angle, for example. Batted ball success rate varies with launch angle, so these players can control the outcome. Likewise, left on base numbers can be controlled through strikeout rates or game strategy. Maybe you have an extreme ground ball pitcher, a skill, who pitches to contact until a runner gets into scoring position. At this point they may turn into a strikeout pitcher, another skill. The men left on base in this case may not represent luck to any degree, but rather an attempt at pitch efficiency.
All methods of measuring luck are all flawed in various ways, and while xStats has its problems, it is at least shrinks the error term. For example, you may look at Noah Syndergaard’s BABIP — it was .334 in 2016 and .279 in 2015. His projected xBABIP going into 2017 is .290. In other words, xStats feels his true talent is closer to .290 plus a luck term.
The luck term is random, so sometimes it may be positive and other times negative. Over time you expect it to melt away, and the stat should trend toward the player’s average skill level. In this case, Syndergaard appears to have a skill level that supports a BABIP a few percentage points below league average.
You can use this sort of reasoning for each of the xStat categories: hits, home runs, batting average, etc. Hopefully it will help you hone in on player skill. You need to take it with a grain of salt, though.
Conclusion
Personally, I find this information most valuable mid-season, when there are few other reliable indicators for player performance. In-game results can take a very long time to stabilize, and as a result they can be questionable. Statcast data, and the more distilled xStats, are a bit more agile. You can use them to inform trades or waiver wire pickups. Since this data is still so new, there may not be many players in your league effectively employing it, which may very well give you a competitive advantage.
We can estimate singles, doubles, triples and home runs after only, perhaps, four dozen batted balls, and we can project this performance into the future with pretty good reliability. We can watch players as they succumb to, and recover from, injury. For the first time, we have a tool that responds to input very rapidly, even if this goes against everything we’ve been taught about baseball analytics over the years.
The data are still very new, and not yet ready for prime time, but it is getting there. I hope, with one more year of data, we can begin to unlock their full potential.
References & Resources
- Hit Probability Chart
- Baseball Savant
- xStats
- Russell A. Carleton, Baseball Prospectus, “The One About Exit Velocity”
- Jeff Zimmerman, RotoGraphs, “Missing Statcast Data with Hyun Soo Kim“
- David Kagan, The Hardball Times, “The Physics of Statcast Errors”
- Micah Daley-Harris, The Hardball Times, “Fixing Batted-Ball Statistics with Statcast”
- Jonathan Judge, Nick Wheatley-Schaller & Sean O’Rourke, Baseball Prospectus, “The Need for Adjusted Exit Velocity”
- Andrew Perpetua, RotoGraphs, “xOBA and Using Statcast Data To Measure Offense”
- Ryan Brock, FanGraphs Community Research, “Introducing xFantasy: Translating Hitters’ xStats to Fantasy”
Steamer Projections would use multiple years of data to come up with their projections. Could xStats correlation improve by using more than just the previous years data.
I certainly hope so! On xstats.org I have “estimated 2017 stats” (I hesitate to call them projections). These numbers combine 2015 and 2016 data, placing a slight emphasis on 2016. Hopefully those numbers will have even less error than the single season version.
Other than that, you would need to resort to using non-xstats data to fill in the missing years, and I’m not sure how much you could learn from that.
This comment has nothing to do with fantasy but –
Looking at the % of value hits chart (which btw is an excellent visual presentation of data), it seems to me that the moneyball opportunity for teams is now via defense (and its likely consequence – smallball/baserunning). Data analytics is always going to tend towards increasing the certainty/predictability (knowledge) of the data that we have. That’s just what humans do. We try to make sense of what we have and what we are looking at – and in so doing we have to assume givenness/randomness/luck for everything that we aren’t looking at or that we don’t have. And since sabermetrics is focused on increasing our knowledge of – and increasing the value of – what is occurring inside the batters box for each discrete data point; the effect is that ‘fielding’ is being relegated to ‘that which reduces saber certainty’ rather than itself being measured.
Going back to that chart, what happens when a team (esp one that plays in a park with a big OF) decides to emphasize defense (range, etc) in its OF? Or even better, use positional defense as a more serious factor in building rosters (more position players who aren’t just platoon powerbats, fewer loogy/roogy) and setting lineups. In chart terms, ‘expand the white areas and reduce the blue/red areas’. Yes park factors will change but the bigger effect on saber data leaguewide will be to increase the uncertainty/variability of that info. To force other teams back ‘into the dark’ about what their data is showing and increase their odds of making actionable errors (saber errors not fielding errors) based on what they think they know.
what about fielding? it may be impossible, but should range, fielding percentage or any kind of defense factor in at all? a ground ball in the hole to francisco lindor may be different than one to someone less able…. how could that factor in to hits/out, etc?
I haven’t found a good way to integrate defense, although I would love to do so. Right now my biggest sources of error seem to be missing data (my biggest problem) and running speed. Defense, while it may be important, isn’t quite as important when compared to those two problems.
Over the full season, against a full gambit of defenders, it may just kinda average itself out naturally. Although I definitely want to find a way to work it in. It is on the checklist right next to shifting.
A few questions/notes:
It seems you’re now using bootstrap aggregation or a random forest model, correct?
When presenting your mean squared error for predictions, it’d be nice if you’d divide by the variance in outcomes to get a coefficient of determination – it gives a much better sense of how accurate the predictions are. Also note that even with a 100PA cutoff, you’re going to get clobbered by the errors of the batters with small samples – you may want to consider being more strict about the cutoff, or else consider weighting the errors by the number of plate appearances.
One of the main things you’re going to want to watch out for is overfitting. You may want to look into various known ways of avoiding this, and see if their application can improve your predictive validity.
Along those lines, it would be interesting to see whether removing the horizontal angle from your calculations decreases predictiveness, or not – I could see it going either way.
Hi, thanks for the notes. I found that eliminating horizontal angle placed too much value on hits to center field and not enough to hits down the lines, which pushed around success rates quite a bit. For example, if you have one guy who hits many balls to short center and another who pulls many balls down the left field line, one may have many singles on these balls while the other has many doubles. The same is true for home runs, where the minimum distance and exit velocity change dramatically between center field and the corners. Anyways, I found it performs better with the horizontal angle included.
Aside from general noise, any idea on why the projections look weird for some guys? For instance, I’m following the Rays catcher battle pretty closely and the numbers are what you’d expect for Casali, Sucre, and Maile. But Mckenry’s projected to be a .340 BABIP guy who slashes .259/.371/.467 and xOBAs .361. This is a guy with just under 1K career PAs and a career .318 wOBA/.294 BABIP, which certainly isn’t bad, but doesn’t seem like it would project what the system does for a 32 year old guy. I’m sure there’s a certain danger in evaluating this one a case by case basis, but I figured I’d see if you have any other thoughts.
Thanks!
Small sample sizes. The projections are based purely on their 2015 data, and the minimum cutoff is 100PA. Basically any player can do anything over 100PA.
Two possible explanations: first, it is a small sample size, and second, that small sample size came in a Rockies uniform.
This is one of the reasons I am not comfortable calling any of this a projection. From what I can tell, the predictive value stems from how high in the tiers of value you can reach. Which I believe is a proportional to bat speed and contact skills. Certain guys seem to be able to hit the ball at high velocity in a slightly larger range of launch angles than other guys, which will ultimately increase your overall success rates.
If you have lower exit velocities, then you rely more on launch angles for value, so your average value per swing drops.
In a small sample, sometimes the velocity+launch angle pattern emerges quickly, and sometimes it can take some time. Once you have the pattern you can reliably predict future results, from what I can tell.
That’s how I think of it anyway. I could be wrong.
Great research.
I think that if you want to use xStats as projections, you should be regressing according to number of plate appearances. Right now, if a player puts up a xOPS of .880 in 100 PA for a season, you project .880 OPS for the next season. If a player puts up an .880 xOPS over 700 PA, your projection for him will be identical.This will inherently put xStats at a huge disadvantage to Steamer.
As a quick fix (until you have multiple seasons of xStats to establish indiv. player baselines), I would regress xStats to MLB-average as a function of PA when trying to use them as projections.