Baseball Coding with Rust – Part 2
This new(ish) programming language is an alternative to other programming languages. (via Public Domain)
{kind=link}
In Part 1, we introduced Rust and built a little program that allowed us to get all the GameDay links for a particular day. Today, we’ll dive right into code and begin the process of building out a complete game from the xml files. As much as possible, I’ll try to explain important concepts along the way as we build out the application. My goal is to deliver a crash course into baseball-centric programming in Rust, complete with code, theory and practical use, without getting too much into the weeds.
Our initial task when dealing with GameDay files is parsing all the various xml files into something we can use. This process is called deserialization, which we’ll be doing a lot of. In Rust, if you’re doing any (de)serialization, you’ll run into a fantastic crate call SerDe. SerDe is amazing, as you’ll soon see. We’ll also need to do serialization (the process of taking something from your program and serializing/writing it to a file) as well, but not in the initial part.
We left off Part 1 with a list of links to folders that contain game-specific data. Each folder has a linescore.xml file and a boxscore.xml file that house certain metadata about the game, such as the stadium, weather, and start time. We’ll also need to parse “players.xml,” which will give us info on the starting lineups, coaches, and umpires. We want our process to work for 2008 rookie-level xml files, as well as more recent, 2018 MLB xml files.
The first thing we’ll need to do is update our Cargo.toml file, which houses all of our application’s dependencies. Cargo will pull the required dependencies from crates.io, based on the version you want. This ensures that the version you’re pulling will always be the same every time you compile your program. At this point, our dependencies should look like this:
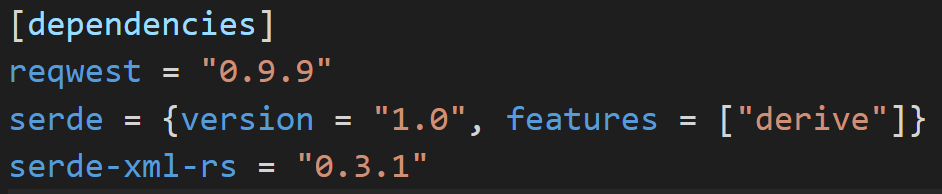
We’re now depending on 3 crates, the reqwest crate to download from the network, serde, to provide serialization and deserialization, and serde-xml-rs to provide xml specific serde support. This will make our lives really easy as we parse data. All we’re going to do is tell serde what our data should look like and it will magically do the rest. Serde is one of the most amazing crates in the Rust ecosystem and provides easy de/serialization for a host of formats (JSON, CSV, YAML, Pickle).
Somewhere in our main.rs file we’ll define our structure that will receive the parsed data:
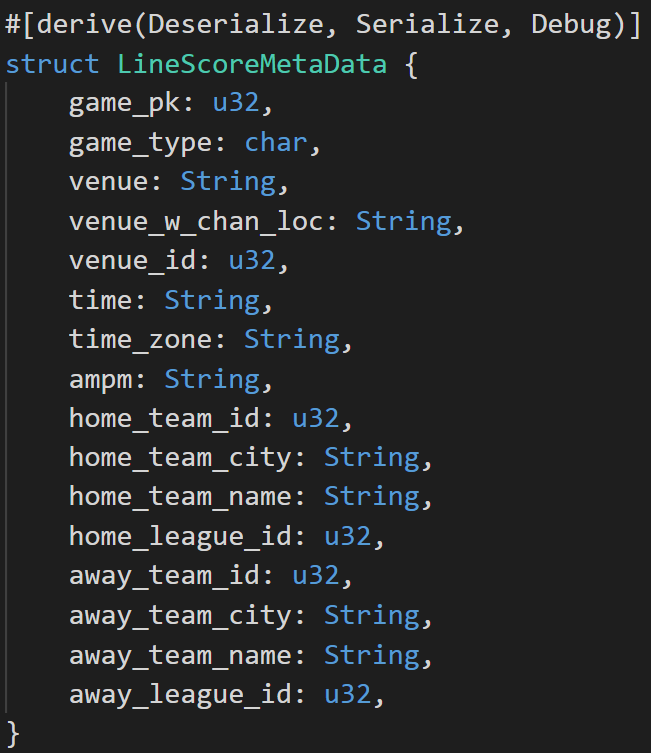
The #[derive(Deserialize, Serialize, Debug)] is a macro that tells the compiler to generate code that will allow this to be (de)serialized, as well as able to print out debug info. We’re using 3 data types in this struct: a 32 bit unsigned integer (u32), a one-byte character (char) and a heap-allocated string (String). We could keep everything as Strings if we wanted, but generally speaking, we want to use more efficient data types whenever we can.
Brief Discussion on Rust’s Option<T> and Result <T, E> Types
Not being explicit about null values is a very big problem. In Rust, if any of our structures or variables might be null, we’ll wrap it in an Option. The <T> means that the Option is generic over any type T. This is programming speak for “you can wrap an Option around anything”. Using the Option type is an explicit way to indicate that your variable or struct might be null. This will force all the other parts of your program to check before using it and will be enforced by the compiler.
If we’re doing an operation that may result in an error, we’ll return a Result <T, E> instead of the thing we’re looking for. This means that we’ll need to be explicit about how we handle errors. While it may feel cumbersome, Rust’s error handling is extremely important for building reliable, correct software. We’ll discuss this more as we go.
All you really need to know for now is that Option <T> will be either Some (T) or None and a Result<T, E> will be either a T (the thing you want) or an E (an error of some sort). If we want to get the value inside the Option or Result, we’ll need to unwrap it.
Linescore Parse Function

If you are new to Rust, this function may seem intimidating. Let’s walk through it step by step.
First we define our function as fn linescore_parse (url: &str) -> Option<LineScoreMetaData> which means it takes in a string slice as input and returns an Option of the LineScoreMetaData structure we defined in the previous section. If we get an error at any step, we’ll return None. If we succeed, we’ll return Some (LineScoreMetaData), which signals that we indeed got a value.
We start by requesting the file from the network with let resp = reqwest::get(url); which returns a Result. Idiomatic Rust would have us use the ? operator to handle errors; for teaching purposes, we’re going to do explicit error handling. If you look closely, the if else block at the bottom of the function does not have a ; at the end. This turns the statement into an expression which means it evaluates into something. In our case, the expression, will return either a None or a Some (LineScoreMetaData), matching our function signature. In Rust, the function implicitly returns the final expression.
The if else statement checks that our Result is ok, meaning it can be unwrapped to get the file we requested. If it is ok, we’ll proceed to unwrap the response from the result.

Match is a powerful feature of Rust, which allows us to do exhaustive pattern matching. Here we’re going to check the text of the response; if it matches to an Ok, we’ll unwrap it into a variable called xml and apply a function to that text. If we get an error, we’ll return None.
The magical parsing all happens in the serde_xml_rs::from_str(&xml.replace('&', "&")).unwrap() code. You’ll notice that there is no error handling in case our parse fails. This is because while I’m still developing the code, I want to see all the times parsing fails. The program will panic (Rust term for crash) anytime parsing fails. The replace function deals with the fact that the XML files contain & signs (it shouldn’t). This can cause errors in parsing, so we simply replace all occurrences of & with &.
Because our function signature tells the compiler that it is going to return a LineScoreMetaData, serde_xml_rs knows to parse the xml text into the structure we defined. I can’t emphasize enough how powerful this is. All we need to do is describe what we want the parsed data structure to look like and the rest is just magically taken care of.
Parallel Processing our Linescore Data
In Rust, parallel processing, when iterating through lists, is really easy to do. I’m talking about real, multi-core parallel processing. We need about 4 letters of Rust code to turn a single-threaded iterator into a parallel iterator.
Now that we’ve abstracted our parsing into a linescore_parse function, we’ll be able to parse each game in its own thread. If you have a modern CPU, this can make computation much faster. We’ll need to use the Rayon crate to enable parallel iterators. First, we’ll update our Cargo.toml file to include Rayon, version 1.10, leaving our dependencies looking like this:
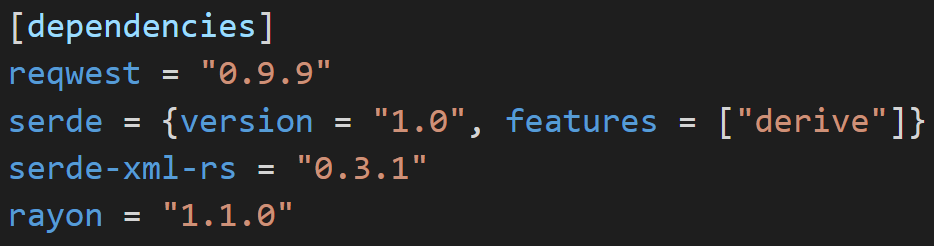
We’ll also need to add use rayon::prelude::*; to the top of our main.rs file.
This is what a parallel iterator looks like:
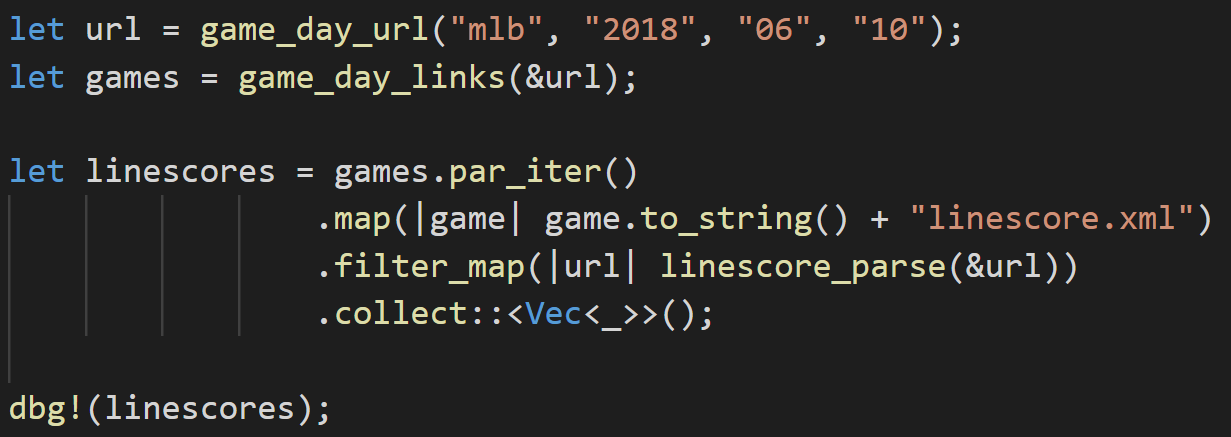
We construct our url and gameday links as per Part 1 of this series. We then take those links and turn them into a list that can be processed in parallel with .par_iter(). If we were making this a single-threaded iterator we would use .iter() instead, hence the aforementioned 4 letters of Rust code.
The first map function takes the value of each item in the list and maps it to the linescore.xml url.
The filter_map takes the url we made in the previous step , maps it to the linescore_parse function and then filters it to only items that parsed correctly. I can’t explain why filter_map isn’t map_filter.
The .collect::<Vec<_>>() collects the list into a Vector. Despite being a strictly typed language, Rust is clever enough to understand that the “_” in the Vec<_> has to be our LineScoreMetaData type that we constructed earlier. How does it know that? We told it earlier that the linescore_parse function must always return a LineScoreMetaData. This guarantees that we can only be collecting that type. The strict typing system actually empowers us to write some pretty flexible code.
Let’s pause for a moment. We’ve just written safe, parallel, performant code that parses arbitrary XML into a custom structure that we defined. And we did this in a systems programming language!
Getting Weather and Attendance Data from boxscore.xml
Let’s start by defining what we want our data to look like:
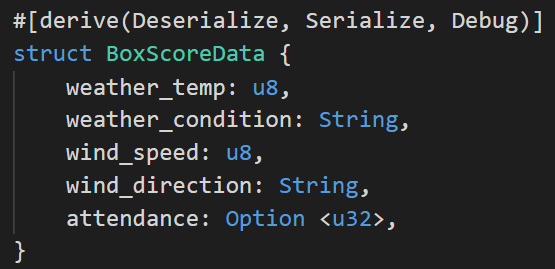
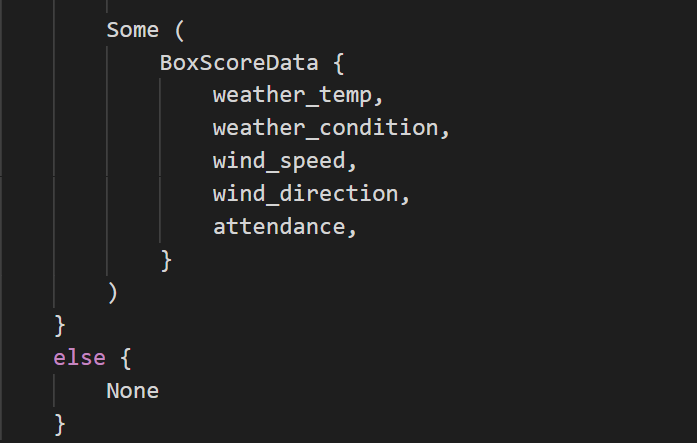
The attendance field is wrapped in an Option since we sometimes don’t have attendance data.
We’ll need to parse the weather and attendance data manually since it’s buried within a <game_info> tag. This function will be quite a bit longer than the linescore_parse() function since we’ll be parsing the <game_info> section that can’t be magically deserialized. Let’s tackle this piece by piece. The <game_info> section has various data enclosed in <b> tags, so to get at the pieces we care about, we’re going to split the text into items every time we see the “<b>” tag.
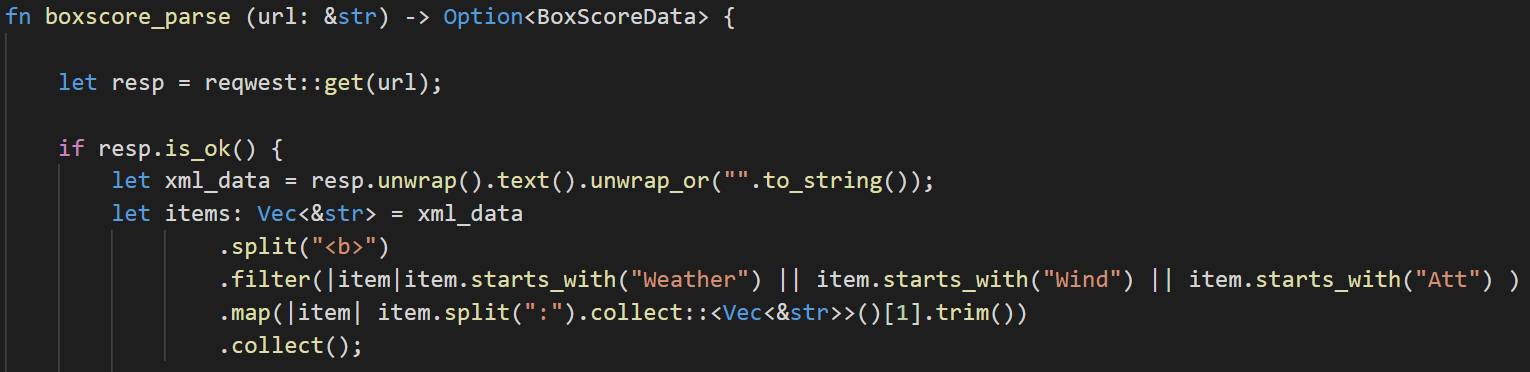
Once we’ve split the text into a list of items, we then filter the list by looking to see if the item starts with “Weather”, “Wind” or “Att”. This should leave us with either 2 or 3 items, depending on whether or not attendance data was encoded into the file.
We’ll then map this filtered list by splitting each item every time we see the “:”, collect this mini-list into a Vector and take the second item. Arrays and Vectors are zero-indexed, which means that [0] is the first and [1] is the second item. The trim at the end removes any excess white space. Finally, we collect this list into the items variable.
Items should now contain 2 or 3 things. Items[0] (the first item in the list) should always contain weather data. Items[1] should always contain the wind data. Items[2], if it exists, should always contain the attendance data. This is a brittle way to parse data, since it will easily break if the underlying structure were to change.
Now that we have a list of useful data pieces, let’s map these to variables.
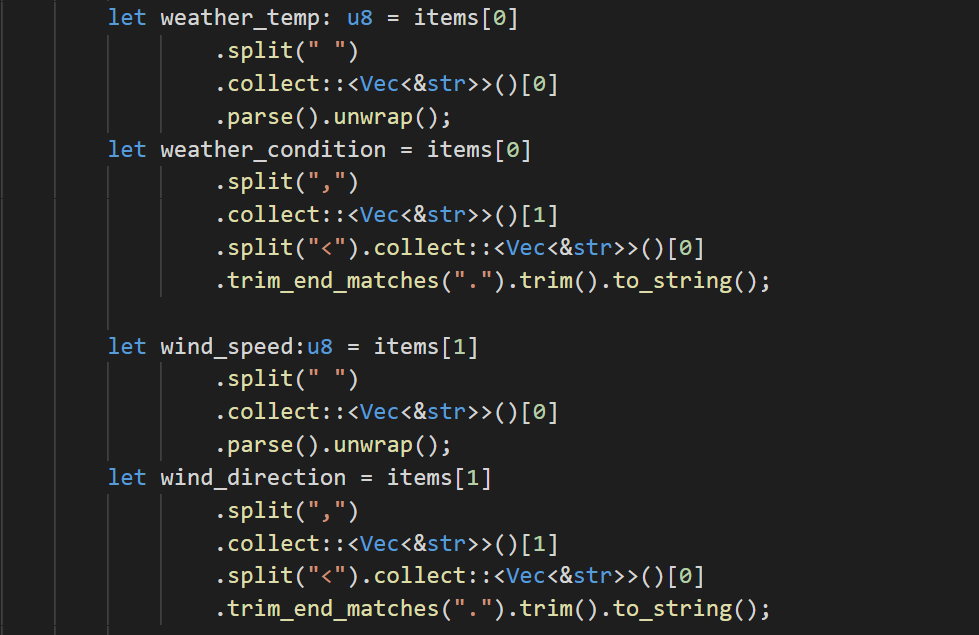
The temperature will look like “90 degrees, sunny.<br/>”, so to get at the temperature, we’ll simply split our first item by a space ” “, then take the 1st item. The .parse().unwrap() parses the string representation of “90” into a the integer representation. Since this could fail, it parses into a Result, which we’ll need to unwrap. We’re not handling the error here, as we want any parsing fails to crash the program while we’re building it out.
To get at the weather condition we’ll first split on the “,” then on the “<” character. The wind speed and wind directions will follow the same logic as the weather variables.
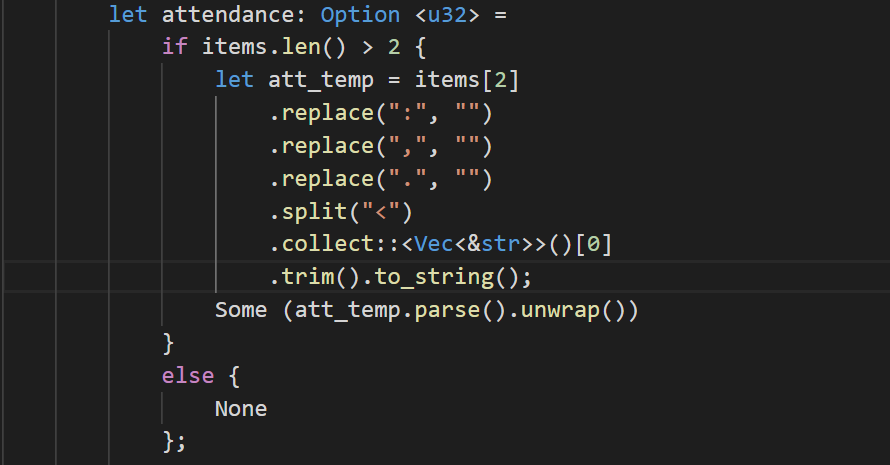
For the attendance piece, we’ll first check to make sure we have more than 2 items. We’ll then strip out any punctuation, split on “<” and then take the first part. We’ll then parse the text into a u32 (32 bit unsigned integer). If we don’t have a 3rd item, we’ll load None into the attendance variable.
Our function will return either Some (BoxScoreData) or None.
Parsing with Nom
The above parsing algorithm will work, but it is not the idiomatic way to do it. If you’re interested in learning the “proper” way to do parsing, have a look at the Nom crate, written by Geoffroy Couprie. Nom is next on my list of Rust things to learn! It has great documentation and should make a lot of the more complicated parsing problems I run into easier to handle (and probably faster).
Closing Thoughts and Part 3 Preview
Today, we continued to build out our baseball application. We built two functions to parse out game-level metadata from the linescore.xml and boxscore.xml files. We used a combination of declarative deserialization, as well as some manual parsing based on splitting text into smaller pieces. Most importantly, we’ve built this in a manner that allows us to do parallel computation, without needing any complex code, nor any knowledge of lock-free data structures, mutexes or atomics.
In part 3, we’ll look at the player data, as well as the play-by-play data. We’ll then serialize our fully built out games (write out our data) to a CSV file that can be loaded into Excel or any other program.
References & Resources
- Sergio Benitez, A Case for Oxidization (via YouTube.com)
- Steve Klabnik and Carol Nichols: The Rust Book
- https://exercism.io/tracks/rust
- The Computer Language Benchmarks Game
- https://www.w3.org/TR/xml/#syntax
- https://www.lucidchart.com/techblog/2015/08/31/the-worst-mistake-of-computer-science/