Baseball Coding with Rust – Part 3
This new(ish) programming language is an alternative to other programming languages. (via Public Domain)
{kind=link}
Welcome back to our Baseball Coding with Rust series. The source code for this series is now available on GitHub. Please take a look and review! The code is evolving, so code you may have seen in previous posts (or even this one) may have been updated.
In Part 1, we introduced Rust, a modern systems programming language, and built out the very first part of our baseball data application. In Part 2, we began deserializing some baseball data from the GameDay xml files. If this is the first article in the series that you are coming across, please read the first two installments before delving into this one.
Getting Data from Players.xml
Now that we’ve gathered the game-level metadata, we’ll need to capture player, umpire, and coach data. To do this, we’re going to rely on SerDe (Rust’s serialization and deserialization framework) that we used in part 2. The players.xml file contains a top level <game>; each <game> has two <team>s and one <umpires> section. Since we’re using declarative deserialization, let’s start by defining our Game structure:
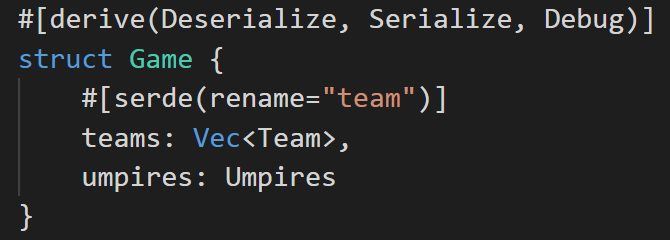
The #[derive(Deserialize, Serialize, Debug)] is a macro that tells the compiler that we’re using this struct for de/serialization and we want to be able to debug it. The compiler will then magically generate the code needed for us. Our Game struct has two components: a list of teams and an umpires section, matching the xml file. We’ll need to annotate the teams section with #[serde(rename="team")] to indicate that we’re looking for team in the xml data, as opposed to teams, our preferred nomenclature.
We’ll now need to define each of the sub structs, specifically the Team and the Umpires structs. Before we create the Team struct, let’s review a concept we touched upon previously: Enums.
Enums in Rust: The “Or” Type (Technically the Sum Type)
Enums, short for enumerations, are referred to as a “Sum” type. Rust has algebraic data types that I only have a surface level understanding of, so we’ll only mention them here in case you’d like to dig into Type Theory at some point. I like to think of Enums as an “Or” type, meaning that our enum can only be one of the enumerated types within. This is as opposed to a struct, which is an “And” type, where it is the product of all the items in it.
A team can be either the Home team or the Away team, perfect for an enum:
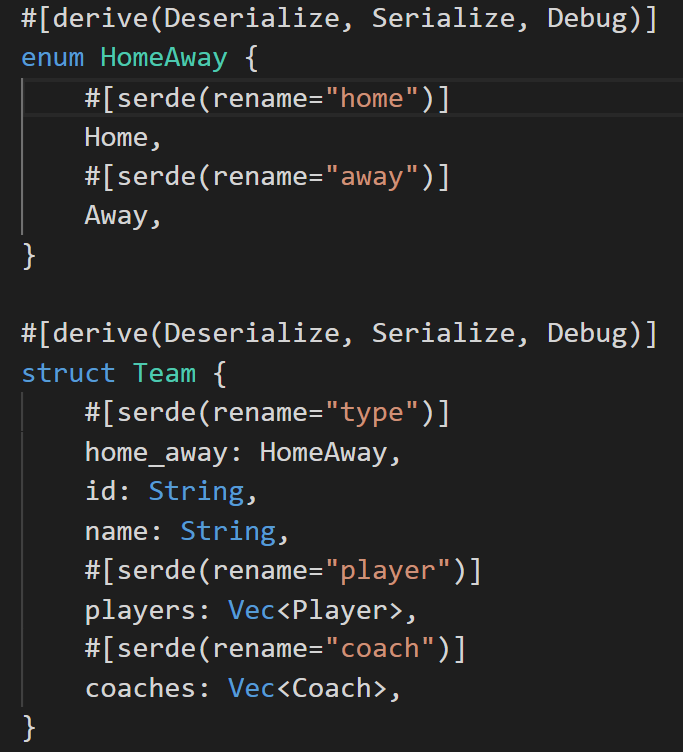
We’ve now declared that we should be looking for a type field (renamed to our HomeAway enum), an id, a name, a list of Players and a list of Coaches. This leaves us with 2 more structs to define:
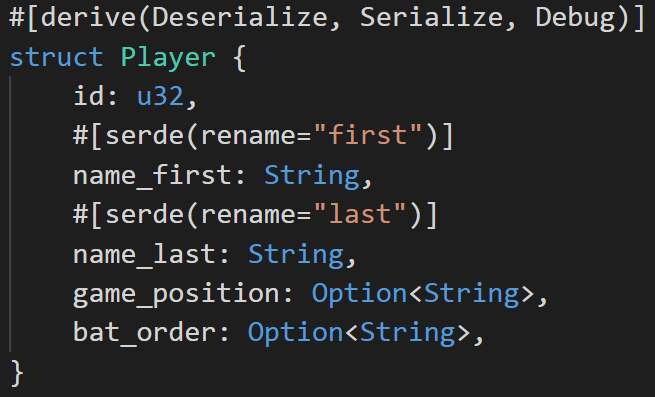
We’ve only declared the variables we care about. Some of the information we need will be contained in the play by play data, so we’ll grab it from there. The game_position is key information, since it indicates the starting position of the 9 fielders. This is wrapped in an option, since only nine of the listed players will be starting. The parent team data would be interesting, except that it is missing info on a lot of players, especially in the older files. We’ll need another way to map minor league clubs to their respective parent teams.
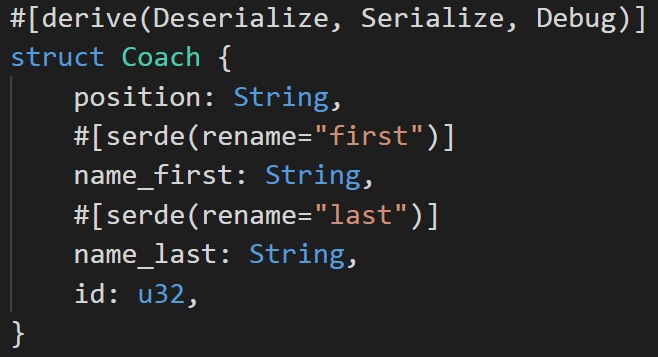
We’ll grab all the coach data as well. This will allow us to map our data to managers, hitting coaches, and pitching coaches should we want to at some point. The data include all the coaches (especially at the major league level), so we’ll be able to build third base coach data as well, in case we want to measure the impact a third base coach has on base running.
The last piece we need is the umpires, which we’ll need to define in two structs: one for the list of umpires, one for the actual umpires. This is to match the xml structure, which has an “Umpires” item as well as individual items. Matching structure is the key to easy deserialization.
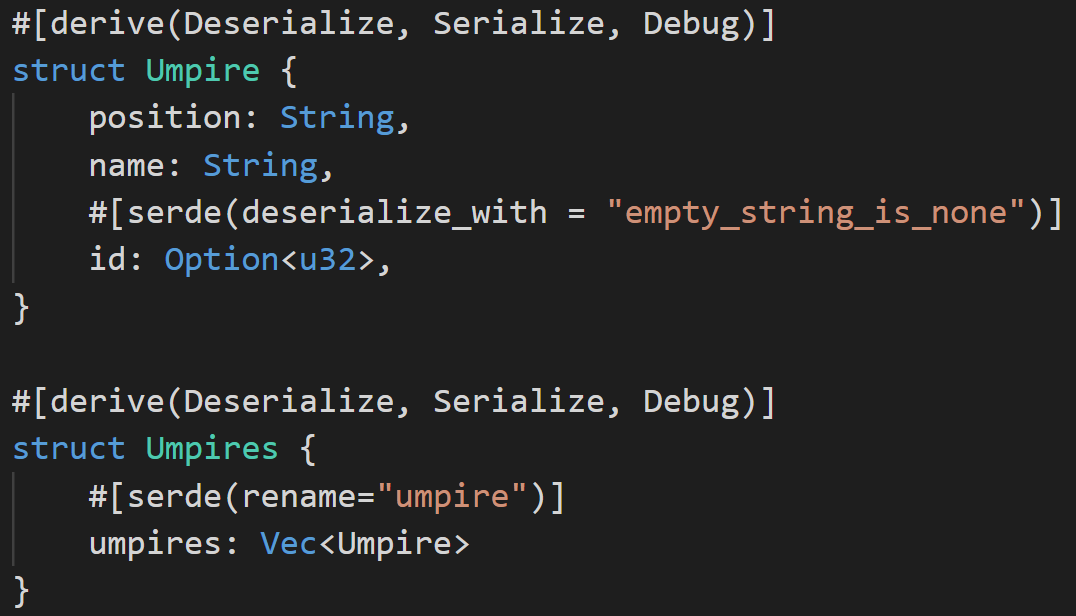
The umpire field, when present for a particular position, will always have an id field. However, sometimes the id field is an empty string, which the deserialization framework views as an error. Due to this, we need to implement a custom deserialization function, which will convert any value in the id field that can’t be converted into a number as a None. SerDe is extremely flexible, so we can write a relatively simple function like this:
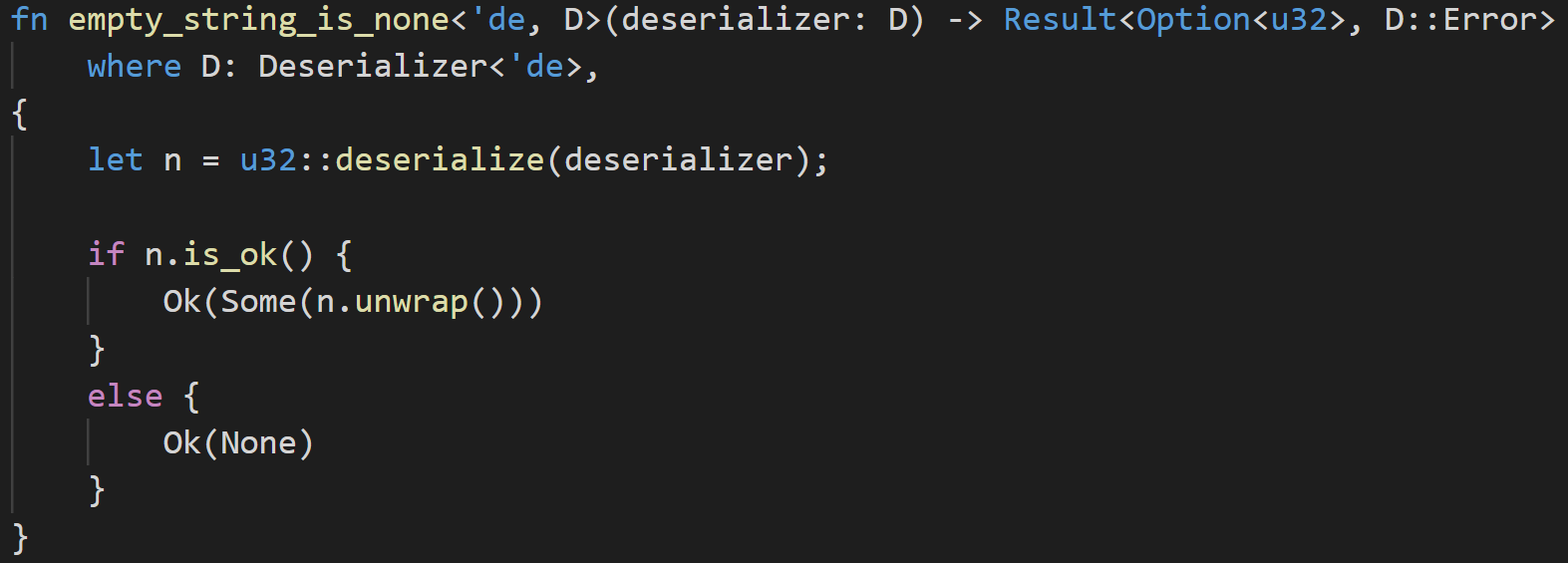
There’s a lot to unpack in this simple function. Our function takes in a deserializer of generic type D. This deserializer that we are feeding to our function must have its deserializer Trait implemented. We’ll dig deeper into Traits in future installments; for now, let’s think of them as contracts that must be satisfied. In essence, its primary role is to guarantee that this item fed into the function is the correct thing to feed into the function. How does the compiler enforce that an item can actually be fed into the function? It uses the Trait of the type. If the type implements the deserializerTrait, then the compiler knows it can be safely passed into the function.
If that all seems a little abstract, don’t sweat it. It took me a good eight months for Traits to “click,” and I’m not sure I fully understand them.

The function body itself does something very simple. We’re basically saying: If there is an error trying to deserialize this item as a u32, return None, otherwise return the value.
Two Lines of Code to Parse the Entire File

We’re introducing a new concept here, specifically the ? operator. The ? operator is a phenomenal feature of Rust once you get the hang of it. If you are interested in learning all about Rust error handling, I warmly encourage you to read Andrew Gallant’s (aka burntsushi) comprehensive treatise on the subject.
In Part 1 we briefly touched upon Rust’s Result type. A Result represents any computation that might, ahem, result in an error. The Result type is an Enum that is either Ok, or an Error of some sort. If it’s Ok, we’ll need to unwrap the computation from the Result.
The ? simply denotes every single point in our logic that might fail and unwraps the result for us. If any of those result in Errors, it will return an Error from the function. This allows for amazingly concise, legible code. If we’re reading this in plain English, we’re expressing logic that says:
- Get the players.xml file for the web
- If you got the file, unwrap the response and try to get the text out of the response
- If you got the text successfully, try to deserialize the text into the Struct we specified above (the Game Struct we defined all the way at the top of this article).
- If at any point you encountered an error, stop computation and return an error.
This workflow is perfect for what we’re doing since we only want to process whole games. At the end of the post, we’ll take a look at the master function, which will coalesce parts 1, 2, and 3 together into one big metadata function.
Pivoting The Umpire Data
Currently, our umpire data is fed to us as a list of umpires. When working with the data, it will be much easier for us to split these data out to individual columns such that we have a field for ump_HP_id, ump_HP_name, etc. To accomplish this, we’re going to use the standard library’s HashMap. A hash map is a data structure that allows for efficient retrieval of values for an arbitrary key. We’ll dig into hash maps in greater detail when we implement parallel hash joins in later installments.
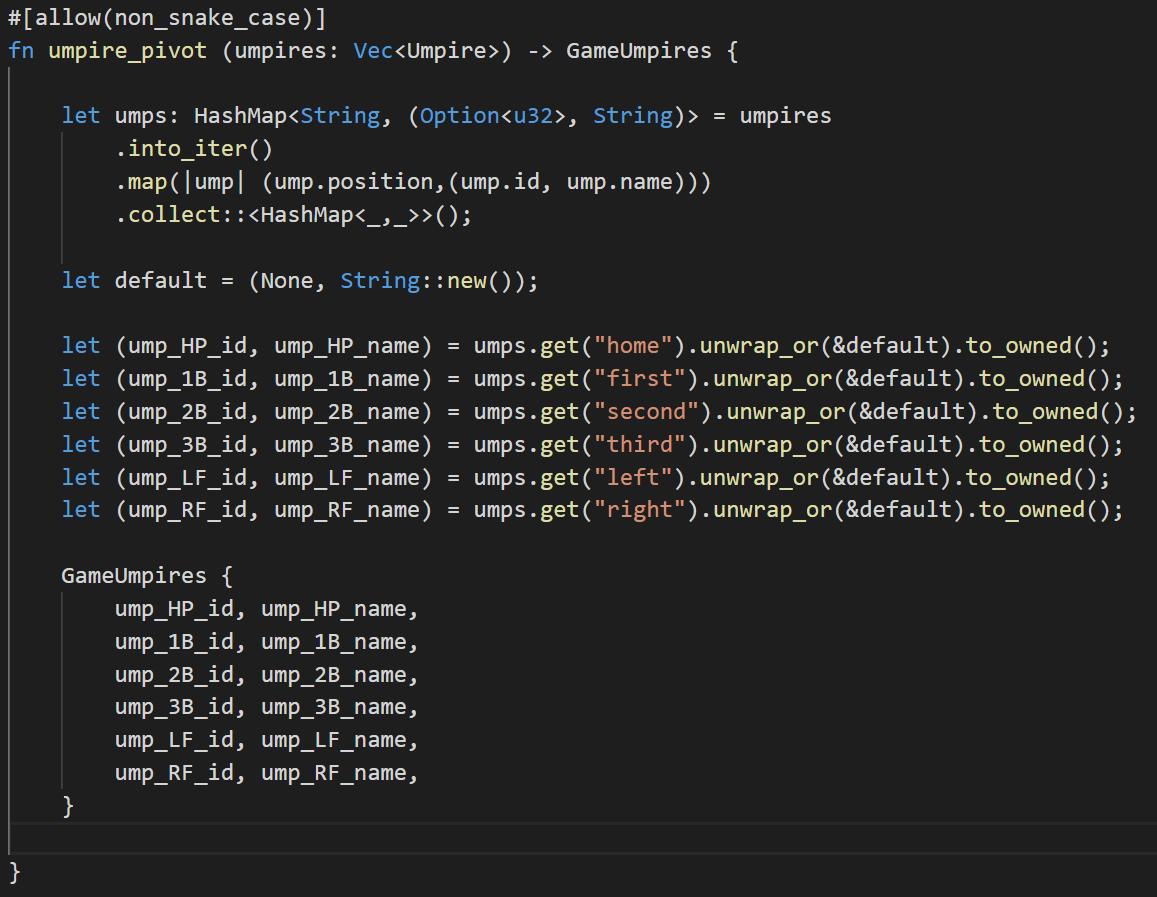
Let’s walk through what’s going on in this function:
First, we take the list of umpires (the Vec<Umpire>) and turn it into an iterator. Now that it’s an iterator (something we can go through one by one), we’re going to map the Umpire struct to a key-value structure, with the position as the key and a tuple of (id, name) as the value. A tuple just means a bunch of variables glued together anonymously. We’ll then collect these into a HashMap. This may seem like a lot of overhead for a simple function (it probably is), however, the beauty of doing this in a low-level language like Rust is that the computational cost is so cheap, it doesn’t really matter.
We then go through each of the six positions and probe (try to get data out of) the hash map using the .get() function. If we can’t find the key in our hash map, we’ll return the default that we defined.
let statement, followed by a tuple, such as let (ump_HP_id, ump_HP_name) = umps.get("home").unwrap_or(&default).to_owned(); the values that the function returns are automatically destructured (mapped) to the matching tuple. Since our hash map returns a tuple, this maps perfectly. If there was a mismatch, the Rust compiler would yell at us.Advanced Error Handling and the ? Operator
If you look at the GitHub repository, you’ll see a lot of code dealing with mapping different error types into the master GameDayError type that was created. This is important, as we’ll want to preserve as much of the original error as possible when we deploy our code. We’ll skip over the internal Error handling plumbing in the codebase. Instead, as we post the cleaned up download and parse function, I want you to focus on 2 concepts and 2 things only:
- The ? operators all over the function
- The
Result<GameData, GameDayError>in the function signature, specifically the GameDayError
The game_download_parse() function will try to process every step. Any time it encounters the ? operator it will try to unwrap the computation. If it gets through all the steps successfully, it will return the GameData. If it fails at any point, it will return a GameDayError. The plumbing mentioned above is there to ensure we retain all the Error information as we encounter different error possibilities.
In Part 2, we went through the linescore.xml and boxscore.xml files. Today, we built out the players.xml parsing logic and added some advanced Error handling. Here’s what the game_download_parse()looks like:
game_download_pars(url: &str)
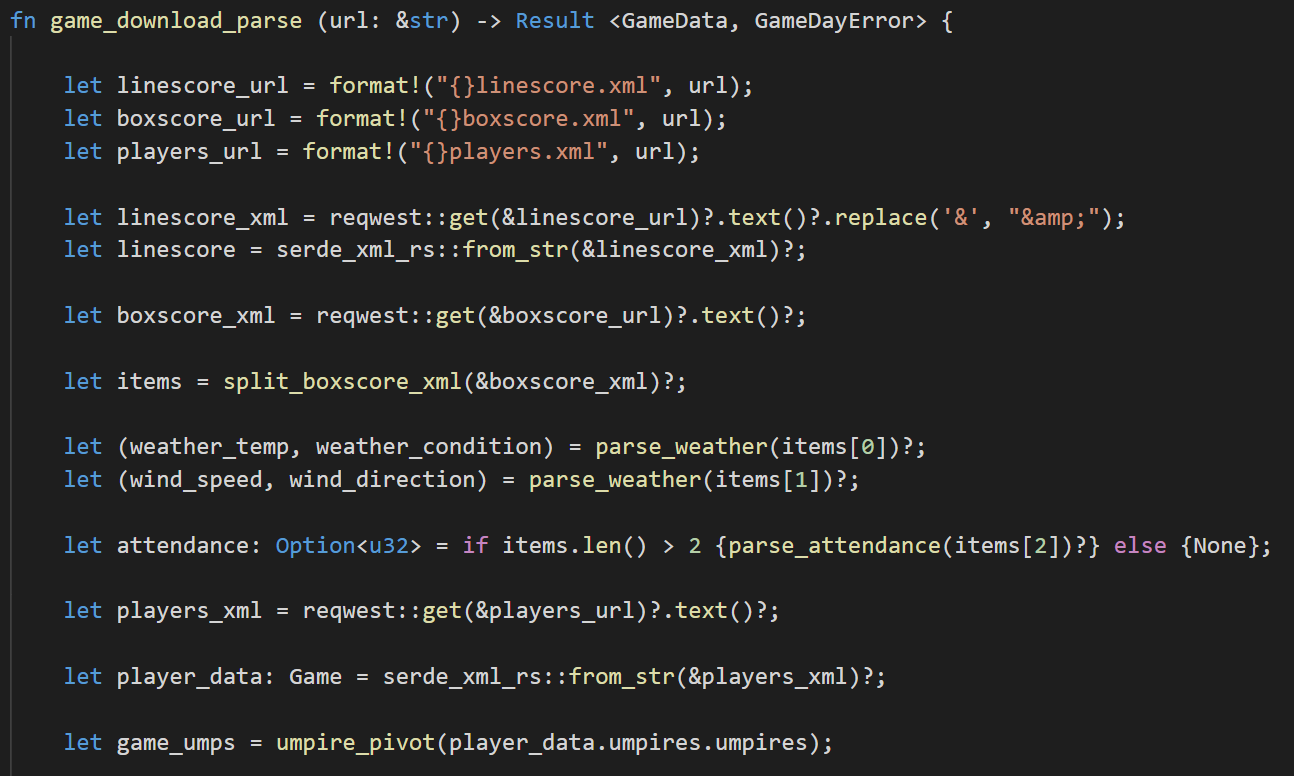
We’ve clearly marked every spot in our program that could fail with a ? and factored out all the specific parsing pieces into their own functions, leaving us with an easy-to-read function that should be very clear as to what each step is doing, even if you don’t know Rust.
Conclusion and Part 4 Preview
We’ve now successfully captured all the metadata we need for any arbitrary game. We’ve also captured the initial player and coach states, which we’ll unpack in Part 4, where we’ll start building the play-by-play data.
Please read the (always-changing) source code on GitHub and leave me any comments, questions or suggestions.
References & Resources
- Sergio Benitez, A Case for Oxidization (via YouTube.com)
- Steve Klabnik and Carol Nichols: The Rust Book
- https://exercism.io/tracks/rust
- The Computer Language Benchmarks Game
- Andrew Gallant: Error Handling in Rust
- GitHub Source Code
please, for the sake of accessibility over aesthetic, embed code snippets from a host like github
+1; I love to cut-and-paste.
I’ve figured out how to do this properly and part 4 onward will have nicely formatted html text snippets.
Thanks again for bringing this up.