Moving Beyond ERA+
In 1988, Storm Davis had a 3.70 ERA. Eighteen years later, Erik Bedard put up a 3.76 ERA. Who had a better year?
The sound you hear is dozens of primates searching Baseball-Reference to look up the ERA+ that corresponds to those pitcher seasons. And of course, they’ll tell you that Davis’s 1988 (102 ERA+) was not as good as Bedard’s 2006 (120 ERA+). Davis pitched in an environment where runs were harder to come by, so his lower ERA was naturally “worth” less.
For those unfamiliar, ERA+ is simply the ratio of park-adjusted league ERA to a pitcher’s ERA. It represents the best of sabermetric thinking: easily accessible, simply computed, and illustrative to the nth degree. ERA+ (and other ratioed statistics such as OPS+) are finding their way into mass media outlets such as Yahoo! and Fox Sports.
But there is something that bothers me about ERA+ as a measure of value (although not necessarily as a measure of performance). A pitcher can be truly awful without bound—with a neglectful manager, he could give up an infinite number of runs. But there is a limit to how good a pitcher can be, because giving up zero runs is the best possible result. What does this mean for ERA+?
Boring Technical Stuff
Let’s back up for a moment and talk about run distributions. I’ve talked about run distributions and their applications before, and if you’re interested in more there are plenty of links at the end of this article. Without going into too many details, the key thing that you need to know is that run distributions are well described by the Weibull equation:
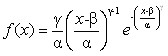
The shape of the curve is uniquely determined when you know the run environment and the runs per game average. In other words, if you know that the average number of runs per game for a particular team (or pitcher) is Y and the league average is Z, you can generate a unique curve that represents the expected distribution of runs scored or allowed.
The following plot shows the run distributions in two extreme run environments: the 1968 NL (3.43 runs/game) and the 1930 NL (5.68 runs/game).
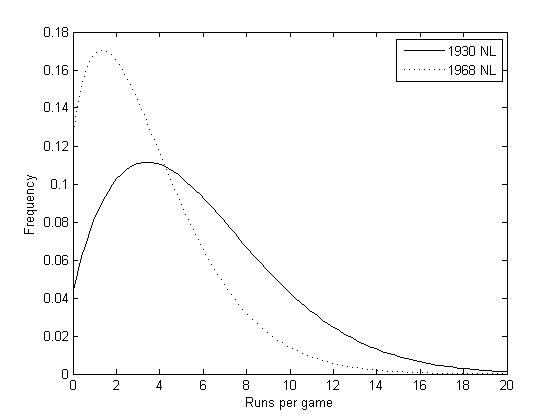
Notice that while the ratio of the average runs/game is 1.65, the ratio of the modes (where each curve peaks) is 2.4 and the ratio of shutouts (where the curves intersect the y-axis) is also about 2.4. This means that a pitcher with an ERA+ of 100 would have had to have thrown a shutout (or equivalent) almost two-and-a-half times as often in 1968 than in 1930. (In case you are mind-boggled that the model predicts that 12.6% of the games in the 1968 NL would have been shutouts, the actual number is 11.4%. The model does generally overpredict shutouts, but it really was that difficult to score even a single run in the Year of the Pitcher.)
All the information contained in the curve, however, is lost in ERA+.
Less Boring Technical Stuff
What does this mean for ERA+? Instead of comparing two leagues, let’s compare a pitcher to league average. To do this, let’s make two assumptions:
1. Pitchers cannot control the shape of their performance distribution.
2. Instead, the shape for all pitchers follows the Weibull distribution.
While I am not sure that the first assumption is true, I have found (non-rigorously) that the second assumption generally is true for large sample sizes. Since the second follows from the first, I believe the first to be generally true as well.
If we make these assumptions, then we can think of an alternative way to compare league-average pitching to actual pitching. Consider two pitchers:
Pitcher ERA lgERA ERA+ RH 3.62 4.69 130 SK 2.76 3.63 131
Pitcher SK has a slight edge over pitcher RH, 131 to 130. But when we compute ERA+, we are only comparing a pitcher’s average to the league average, and we lose the information contained in the shapes of the curve that describe their performance and the performances of their peers. More accurately, we over- or under-stating the value of preventing runs.
Let’s try a crude way to rectify this. Conceptually, what we want to do is reward a pitcher every time his performance is better than the league mean. But since we know the distribution of run scoring, we can do better than just picking the average runs scored per game; we can compute the 50th percentile of pitching performances. Then we simply count the number of times the pitcher in question exceeded the 50th percentile performance of the league.
Take RH as an example. Start with the ERA of the league he pitched in, 4.69, and use the Weibull equation to find the 50th percentile league-average performance. That is a relatively simple computation, and in this case the answer is 4.24. The 50th percentile is always less than the average because the curve has a long tail.

Then generate a curve based on RH’s ERA (3.62) and his run environment (league-average ERA, 4.69). Remember, we’re not looking at the pitcher’s actual distribution of performance, but rather what the distribution would have looked like if we had an infinite sample size at the same level of performance. Now all we have to do is count the frequency with which he exceeded the 50th percentile league-average performance. The computation is shown graphically below:

Multiply the result by 100 and you have an easy interpretation: the frequency with which a pitcher exceeds the 50th-percentile performance of the league. A score of 50 is by definition average; 0 is the worst score possible and 100 is the best.
And if you’re really a nerd, you’ll recognize the mathematical shorthand of this process as:

No More Technical Stuff
Is there a point to all these mathematical gymnastics? Take the above two pitchers:
Pitcher ERA lgERA ERA+ mERA+ SK 2.76 3.63 131 62.3 RH 3.62 4.69 130 62.9
Not a big difference, to be sure. But who knew Roy Halladay’s (RH) career run prevention rate was more valuable than Sandy Koufax’s (SK)? Remember that I’m not trying to make judgements of performance, only judgements of value. Halladay’s run prevention rate (to date) has been slightly more valuable than Koufax’s because of run environments. ERA+ helps us correct this problem, and mERA+ gets us a few inches closer to truth.
But as you could have guessed by now, mERA+ doesn’t make too big difference…until you go way out to the edge. I don’t mean to pick on Koufax, but he’s a very good example since he worked in some of the friendliest pitching conditions in history. It is often pointed out that Pedro Martinez had a comparable or better peak to Koufax, and ERA+ is used as the measuring stick. But I don’t think we understand just how amazing Pedro’s peak performances were, considering his pitching environment. Take Pedro in 2001 and Koufax in 1964. ERA+ gives Pedro the slight edge, 189 to 187. But mERA+ is even friendlier to Pedro, giving him the edge 80.5 to 76.0.
That’s right, in 2001, Pedro’s performance (as translated to the Weibull distribution) was better than the 50th percentile of league performance just over 80% of the time. Koufax in 1964 was at 76%. Both are impressive, Pedro’s more so. By contrast, the most dominating pitcher in the majors last year, Johan Santana, was at 73%. Only a few percentage points and the skewed lens of a run environment comprise the difference between dominating and historic.
Beyond ERA+
Let’s take at the top 10 pitchers by career ERA+ and see how mERA+ adjusts their value:
Pitcher ERA lgERA ERA+ mERA+ Pedro Martinez 2.81 4.49 159.8 72.8 Lefty Grove 3.06 4.54 148.4 69.4 Walter Johnson 2.17 3.17 146.1 66.0 Dan Quisenberry 2.76 4.04 146.4 67.8 Hoyt Wilhelm 2.52 3.68 146.0 67.1 Joe Wood 2.03 2.97 146.3 65.5 Ed Walsh 1.82 2.63 144.5 64.3 Roger Clemens 3.10 4.46 143.9 67.8 Johan Santana 3.20 4.59 143.4 67.9 Roy Oswalt 3.05 4.35 142.6 67.2
In other words, we’ve been underestimating how difficult run prevention in high-offense environments are. Smokey Joe Wood and Ed Walsh were dominating pitchers in their time, but their particular ability to keep runs off the board just weren’t as valuable back then as it is now. Even Walter Johnson, the Big Train himself is cast in a new light, passed over by Roger Clemens, Johan Santana, and Roy Oswalt. (In fairness, the latter two haven’t seen their decline phase. Then again, maybe Clemens hasn’t either!)
Should we think less of the skills of Johnson, Wood, and Walsh? I don’t know; I think it’s more appropriate to say that we’re assessing value and not performance. But in offense-starved eras, providing value by pitching better than a 50th-percentile performance is tough because—as I said earlier—there is a lower limit to allowing runs. That limit is zero runs, and eras that push that limit make it more difficult for pitchers to provide value.
How about single seasons (post-1900)? Remember that we’re translating average performance (ERA) into a Weibull distribution. The actual distribution in a season may not follow the Weibull distribution, but the Weibull is a good representation of what that average performance would translate to in a larger sample size. In other words, you’ll need a grain of salt bigger than the ones you have been taking.
Pitcher ERA lgERA ERA+ mERA+ Pedro Martinez 1.74 4.97 285.6 94.2 Dutch Leonard 0.96 2.68 279.2 85.7 Greg Maddux 1.56 4.26 273.1 91.5 Walter Johnson 1.14 2.96 259.6 85.3 Greg Maddux 1.63 4.23 259.5 90.1 Bob Gibson 1.12 2.90 258.9 84.9 Mordecai Brown 1.04 2.62 251.9 82.7 Pedro Martinez 2.07 5.07 244.9 90.7 Walter Johnson 1.39 3.34 240.3 84.5 Christy Mathewson 1.28 2.93 228.9 81.5
The awesomeness of this generation’s pitchers cannot be denied. Martinez and Greg Maddux lead the field in mERA+, and Dutch Leonard’s incredible sub-1.00 ERA is just not as incredible when we look more carefully through the lens of run environments. Pedro’s 94.2 mERA+ in 2000 is absolutely unreal—his performance (re-distributed over a Weibull curve) was better than the 50th-percentile league average performance almost every time out.
None of this, of course, is meant to discourage the use of ERA+. ERA+ and other numbers normalized to league average are among the most illustrative and accessible of the “new” statistics. They have clear interpretations, are easy to compute, and come as close to a full story as one number can. Furthermore, mERA+ has a number of improvements that could be made; in the future I would like to incorporate the marginal value each run has on the probability of winning (which is simple conceptually but computationally more involved).
But when we start looking at the boundaries, it sometimes helps to sacrifice some simplicity for some insight. And while analytics have helped us recognize that we’ve recently had the pleasure of watching all-time greats in Maddux, Martinez, and Clemens, I still think we’re selling these guys short. Runs have been so cheaply acquired over the past fifteen that, despite all the plaudits, their careers are criminally unrecognized. Part of the reason is that the differences in run environments have a much greater effect on how we should value pitching performances than is generally assumed. Using run distributions helps us re-assess the value of great pitching in different eras.
References & Resources
There is nothing better than a primary source, so if you are interested in run distributions and aren’t scared by intergrals, be sure to catch Professor Steven Miller’s original treatise on Weibull Distributions (pdf).
I’ve used the Weibull distribution a few times now. Fitting methodologies as well as run distribution charts for 1998-2004 can be found here. I looked at the 2005 AL West race seen through the eyes of Waloddi Weibull here and here. The use of run distribution charts to find “feast or famine” offenses can be found here and here
The incomparable Dave Studeman has also written about run distributions right here at THT. And the inimitable Tangotiger has run distribution program located at the very bottom of his website. Keith Woolner took a look at run distributions way back in 2000 and developed a fairly complex model.
As always, Sean Forman’s Baseball Reference was invaluable.